mT5, 쉽게 이해하기 — 모든 일을 '텍스트→텍스트'로 푸는 101개 언어 모델 (왜 query rewriting·파라미터 추출에 쓸까)
2020년 구글 mT5가 무엇인지 101 수준으로 쉽게 풀고, 왜 대화형 에이전트의 query rewriting(질문 다시쓰기)과 parameter extraction(파라미터 추출)에 mT5가 잘 맞는지 이유를 그림으로 설명합니다.
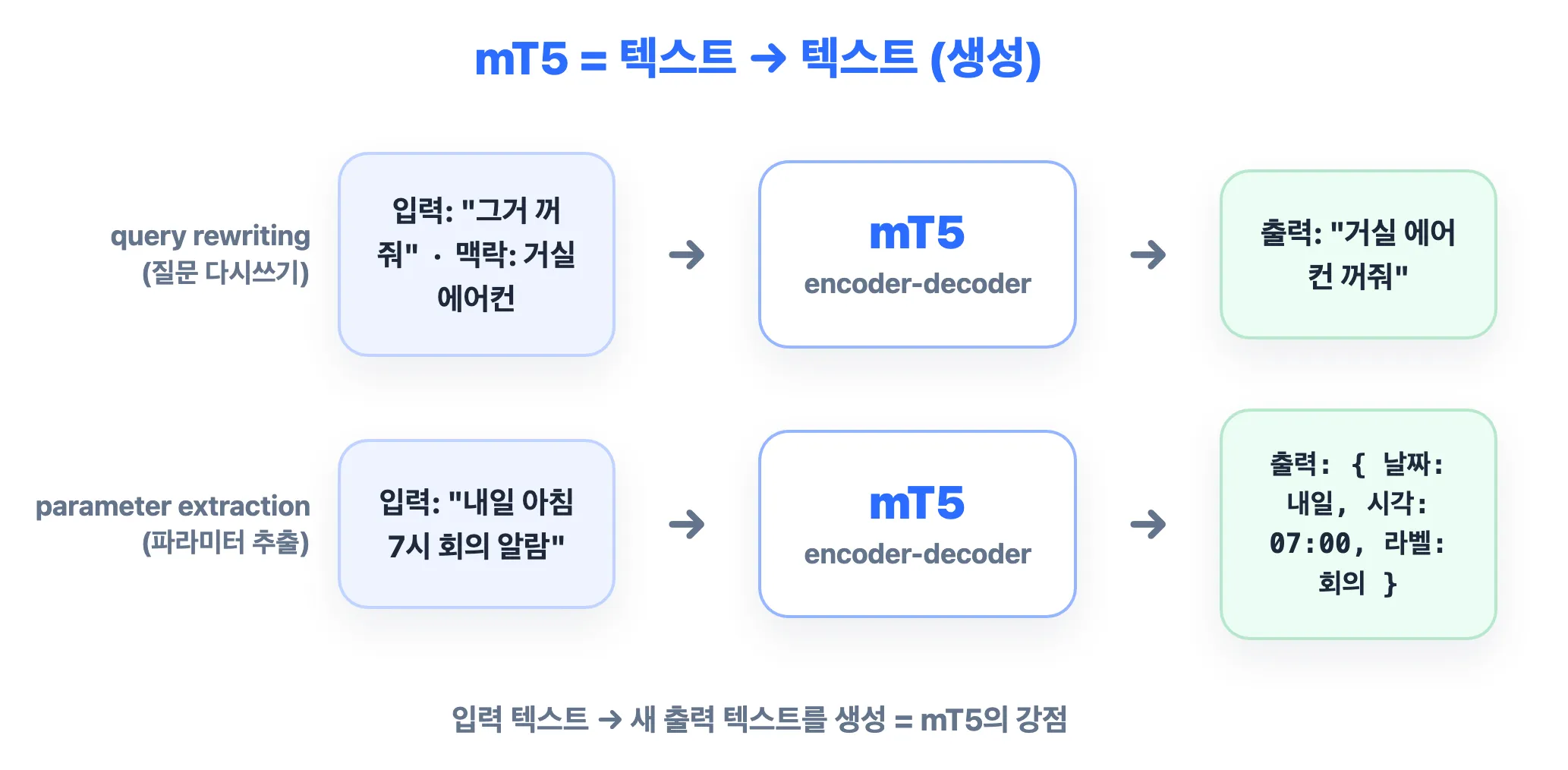
“mT5가 뭐냐”고 하면, 101개 언어를 다루며 모든 작업을 “텍스트 넣고 → 텍스트 받기”로 통일한 모델입니다. 2020년 구글이 공개했고, 영어 위주이던 T5를 다국어로 확장한 버전이죠. 번역·요약·질문 다시쓰기처럼 새 문장을 만들어내는 일에 강합니다. 이 글은 쉽게 풀고, 마지막에 왜 에이전트의 query rewriting·parameter extraction에 mT5를 쓰는지 설명합니다.
1. 한 문장으로
mT5 = 101개 언어를 다루는 encoder-decoder 모델. 모든 일을 “텍스트 → 텍스트” 라는 한 형식으로 적어서, 새 텍스트를 만들어내는 데 강하다.
2. 이름 뜯어보기
mT5 = multilingual + T5. 그리고 T5 = Text-to-Text Transfer Transformer.
이름의 핵심은 “Text-to-Text” 입니다 — 입력도 텍스트, 출력도 텍스트로, 모든 작업을 똑같은 형식으로 적는다는 뜻이에요.
3. 핵심 아이디어 — 모든 일을 “텍스트 → 텍스트”라는 한 틀로
보통은 작업마다 모델 구조가 따로입니다(번역기 따로, 분류기 따로). T5/mT5의 아이디어는 모든 작업을 “입력 텍스트 → 출력 텍스트”라는 똑같은 형식으로 적는다는 것입니다. 작업이 뭐든 입력도 글, 출력도 글로 통일하는 거죠.
| 하고 싶은 일 | 입력 (텍스트) | 출력 (텍스트) |
|---|---|---|
| 번역 | translate English to Korean: Hello | 안녕하세요 |
| 요약 | summarize: (긴 글) | (짧은 요약) |
| 질문 다시쓰기 | 그거 꺼줘 [맥락: 거실 에어컨] | 거실 에어컨 꺼줘 |
여기서 꼭 짚을 점이 있습니다. 이건 작업을 적는 “형식”을 통일한 것이지, 아무 지시나 알아서 척척 수행한다는 “능력”이 아닙니다. 위 표처럼 입력 앞에 translate English to Korean: 같은 말을 붙이는 방식은, 그 작업을 하도록 미리 학습된 모델일 때 통합니다. mT5 그대로는 아직 그 일을 못 해요. (왜 그런지, 어떻게 가르치는지는 6절에서.)
4. 구조 — encoder-decoder (이해 + 생성)
- BERT: encoder만 (읽고 이해)
- GPT: decoder만 (이어서 생성)
- T5 / mT5: encoder + decoder 둘 다 → 입력을 이해(encoder) 하고 새 텍스트를 생성(decoder) 합니다.
그래서 입력을 받아 전혀 다른 새 텍스트를 만들어야 하는 일(번역·요약·재작성)에 자연스럽습니다.
5. 다국어 — 101개 언어
- mC4라는 거대 다국어 웹 데이터(Common Crawl 기반)로 학습 → 101개 언어(한국어 포함)를 다룹니다.
- 한 모델이 여러 언어를 같이 배워서, 데이터가 적은 언어도 다른 언어에서 배운 지식을 나눠 씁니다(cross-lingual). 다국어 서비스에 유리하죠.
6. 중요 — mT5는 작업을 “파인튜닝”으로 배운다
3절에서 본 “텍스트 → 텍스트”는 작업을 적는 형식이지, 아무 지시나 알아서 수행하는 능력이 아닙니다. 흔한 오해를 여기서 짚고 갑니다.
- mT5의 사전학습은 문장의 빈 토막을 복원하는 게임(span corruption) 하나만 했습니다.
query rewriting같은 구체적 작업은 배운 적이 없어요. - 게다가 mT5 기본 체크포인트(mt5-small/base/…)는 순수 비지도 학습만 거친 “날것”이라, ChatGPT처럼 지시문을 바로 따르지 못합니다. 그래서
"이 문장 다시 써줘"라고 프롬프트만 줘서는 제대로 동작하지 않습니다.
그래서 mT5로 어떤 작업을 시키려면, (입력 → 정답 출력) 예시를 모아 파인튜닝(fine-tuning) 해서 그 일을 가르쳐야 합니다.
| 입력 (text) | 목표 출력 (text) |
|---|---|
그거 꺼줘 [맥락: 거실 에어컨] | 거실 에어컨 꺼줘 |
거기 날씨 어때 [맥락: 부산] | 부산 날씨 어때 |
- 데이터는 보통 수백~수천 쌍, 모델은 작은 mT5-small/base 면 시작하기 충분합니다.
- 처음부터 다시 학습(재학습)할 필요는 없습니다. 이미 101개 언어를 익힌 모델 위에 작업만 얹는 것이니까요.
- 지름길: 이미 instruction이 튜닝된 변종(예: mT0)을 쓰면 적은 데이터·few-shot로 더 쉽습니다. 그래도 품질을 확실히 하려면 본인 데이터로 한 번 파인튜닝하는 게 정석입니다.
7. 왜 query rewriting에 mT5를 쓸까
Query rewriting(질문 다시쓰기) = 사용자의 모호하거나 불완전한 말을, 시스템이 처리하기 좋은 명확한 문장으로 고쳐 쓰는 일입니다.
- 예: 대화 중 “그거 꺼줘” → (앞 맥락 반영) “거실 에어컨 꺼줘”. 대명사 풀기, 생략된 말 복원, 오타 교정 등.
mT5가 맞는 이유:
- 출력이 “새로운 문장” 입니다. 보기 중 하나를 고르는 게 아니라, 매번 다른 길이의 새 텍스트를 지어내야 합니다 → 분류로는 불가능한, 전형적인 생성(seq2seq) 문제예요.
- mT5는 입력을 이해(encoder)하고 고쳐 쓴 문장을 생성(decoder)하는 text-to-text 구조라 이 일에 잘 맞습니다.
- 101개 언어를 다루니, 여러 언어로 들어온 말도 다시 써줄 수 있습니다.
단, 6절에서 말했듯 mT5 기본 모델이 이걸 바로 하지는 못합니다. (입력 → 다시 쓴 쿼리) 예시로 파인튜닝해야 실제로 작동합니다.
8. 왜 parameter extraction에도 mT5를 쓸까
Parameter extraction(파라미터·슬롯 추출) = 행동을 실행하는 데 필요한 값들을 뽑아 정리하는 일입니다.
- 예: “내일 아침 7시에 회의 알람” →
{ 날짜: 내일, 시각: 07:00, 라벨: 회의 }
mT5가 맞는 이유:
- 단순히 단어에 표시만 하는 게 아니라, 값을 다듬어 새 형식으로 만들어야 할 때가 많습니다. “아침 7시” →
07:00, “내일” → 실제 날짜처럼 변환·정규화가 필요하죠. 이건 원문에 그대로 없는 텍스트를 생성하는 일이에요. - mT5는 “발화 → 구조화된 텍스트(JSON 비슷한 형식)“를 그대로 생성할 수 있어서, 값 정규화·누락 채우기·형식 통일을 한 번에 처리합니다.
- 역시 다국어 입력을 함께 다룹니다.
이 작업도 마찬가지로, (발화 → 구조화된 값) 예시로 파인튜닝해서 가르칩니다.
9. BERT와의 분업 — “고르기는 BERT, 새로 쓰기는 mT5”
대화형 에이전트의 전형적인 흐름은 이렇습니다.
- 질문 다시쓰기 (mT5) — 모호한 말을 명확하게 고쳐 쓰기.
- 행동 분류 (BERT) — 무슨 action인지 정해진 보기 중 하나로 고르기.
- 파라미터 추출 (mT5) — 실행에 필요한 값을 뽑아 정리하기.
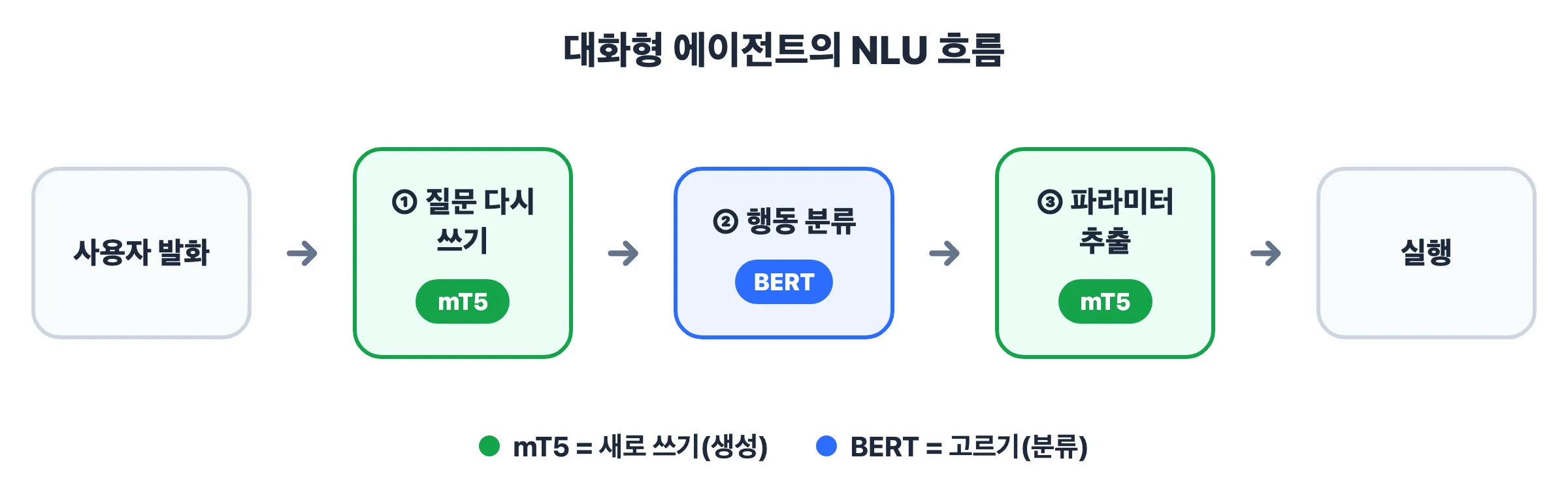
- 고르기(정해진 보기 중 선택) = BERT (encoder, 빠르고 정확)
- 새로 쓰기(가변 텍스트 생성·변환) = mT5 (encoder-decoder, 생성 가능)
그래서 query rewriting·parameter extraction처럼 새 텍스트를 만들어내는 일은 mT5가 맡습니다. (BERT든 mT5든, 각자 맡은 작업으로 한 번씩 파인튜닝해서 붙입니다.)
10. 크기
- Small 300M / Base 580M / Large 1.2B / XL 3.7B / XXL 13B
용도·예산·지연(latency)에 맞춰 고릅니다. 에이전트의 실시간 부품으로는 작은 쪽(Small/Base)을 fine-tune해서 자주 씁니다.
정리
- mT5 = T5(text-to-text)의 다국어판, 101개 언어, encoder-decoder 구조 (2020, 구글)
- “텍스트 → 텍스트”는 작업을 적는 형식일 뿐 — mT5 기본 모델은 지시를 바로 따르지 못한다. (입력 → 출력) 데이터로 파인튜닝해서 작업을 가르쳐야 한다 (처음부터 재학습은 불필요).
- 그래서 에이전트에서 query rewriting(말 다시쓰기)과 parameter extraction(값 뽑아 정리)을 맡음 — 둘 다 “새 텍스트를 만들어내는” 일이라서
- “고르기”는 BERT, “새로 쓰기”는 mT5로 분업
참고 자료: mT5 (Hugging Face docs), 원논문 Xue et al., 2021, “mT5: A Massively Multilingual Pre-trained Text-to-Text Transformer”.