MiniLM, 쉽게 이해하기 — 문장을 '의미 숫자'로 바꾸는 작고 빠른 모델
보편적으로 말하는 MiniLM(all-MiniLM-L6-v2)이 무엇인지, 왜·어떻게 쓰는지, 시맨틱 검색·RAG·클러스터링 같은 실제 사용 예를 도식으로 쉽게 설명합니다.
“MiniLM이 뭐냐”고 하면 사실 세 가지가 한 이름으로 섞여 있지만, 실무에서 보편적으로 말하는 MiniLM은 문장 임베딩 모델 all-MiniLM-L6-v2 입니다. 작고 빠르면서 공짜라서, 시맨틱 검색·RAG의 사실상 기본값으로 쓰이죠. 이 글은 그림 위주로 쉽게 풀어봅니다.
1. 한 문장으로
MiniLM = 문장을 “의미 좌표(숫자 384개)“로 바꿔주는 작고 빠른 번역기.
사람의 문장은 컴퓨터가 직접 “비슷한지” 비교할 수 없습니다. MiniLM은 문장을 384개의 숫자(벡터) 로 바꿔서, 의미가 비슷한 문장은 비슷한 숫자가 나오도록 만듭니다. 이 숫자 묶음을 임베딩(embedding) 이라고 부릅니다.
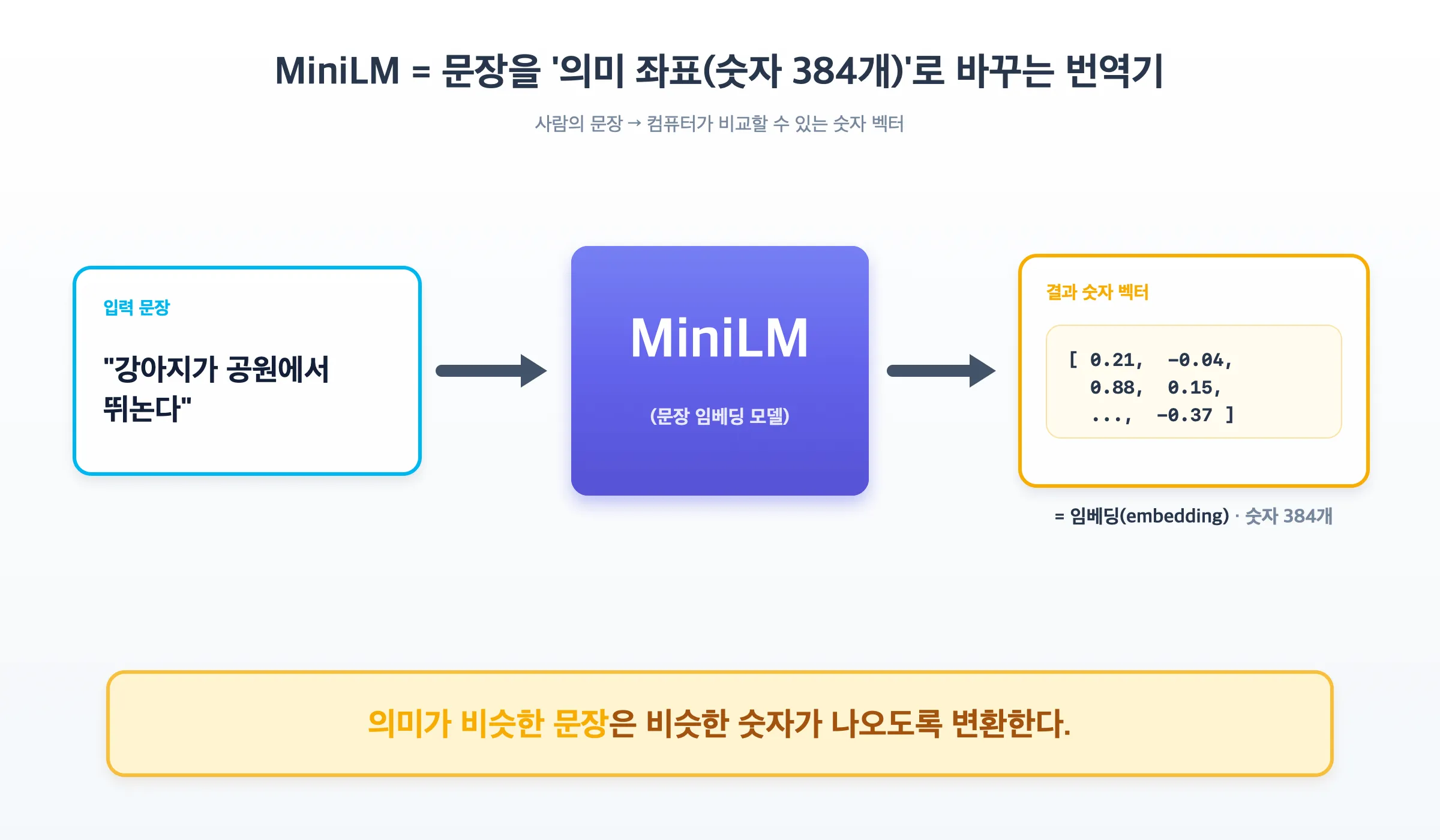
2. 핵심 개념 — “임베딩”이란
문장을 좌표로 바꾸면, 의미가 가까운 문장은 공간상에서도 가까이 모입니다. 실제로는 384차원이라 사람 눈에는 안 보이지만, 2차원으로 줄여 그리면 이런 느낌입니다. 두 문장이 “얼마나 비슷한가”는 두 벡터 사이의 각도, 즉 코사인 유사도(-1 ~ 1)로 잽니다.
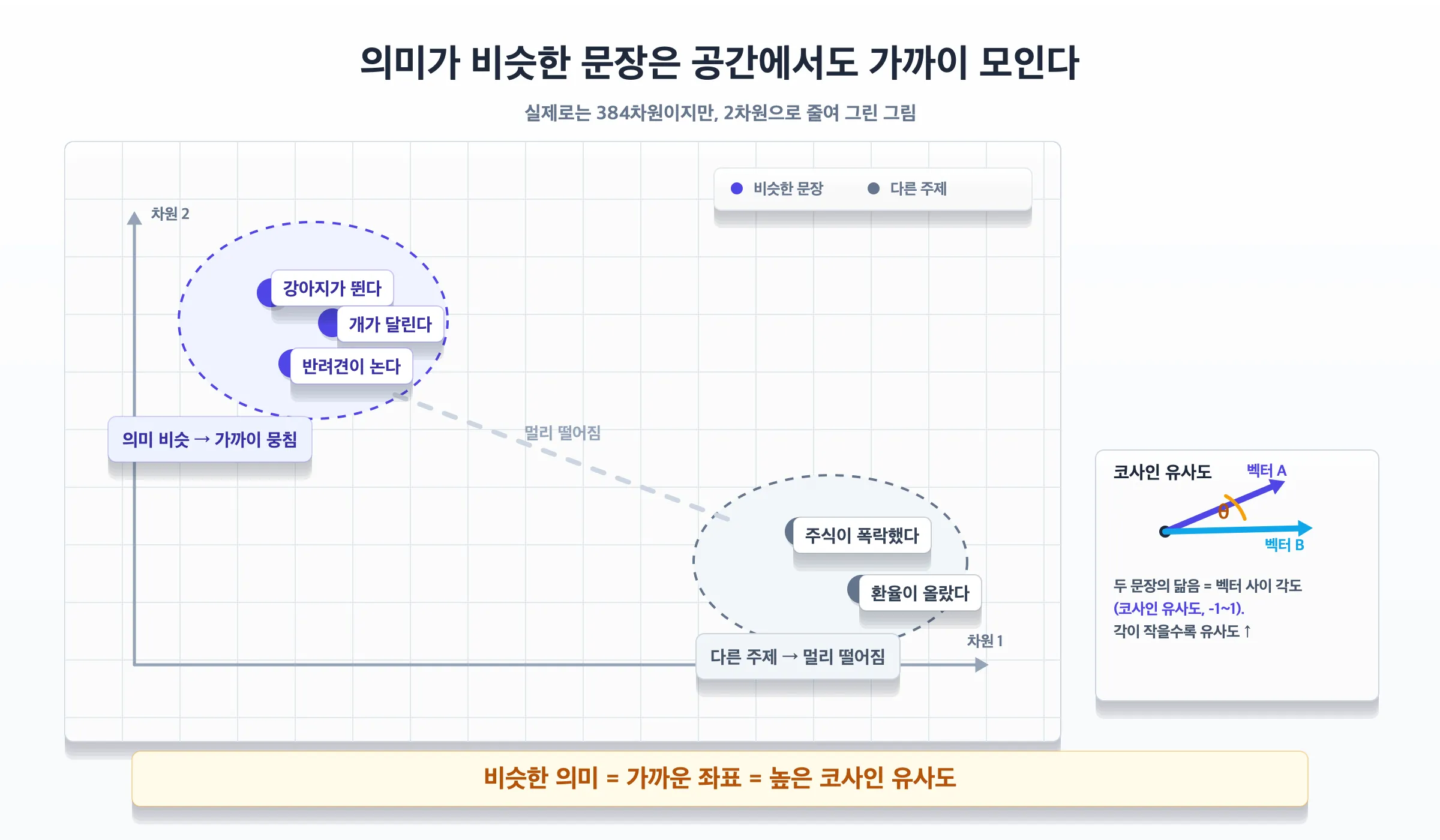
3. 왜 MiniLM을 쓰는가? (Why)
| 이유 | 설명 |
|---|---|
| 작고 빠름 | 약 22MB / 22M 파라미터. CPU에서도 빠르게 동작 (GPU 불필요) |
| 무료·오픈 | Apache 2.0 라이선스, 상업적 사용 자유 |
| 가성비 | 크기에 비해 정확도가 좋아 “기본값”으로 자주 채택 |
| 로컬 실행 | 외부 API 호출 없이 내 서버/노트북에서 동작 → 데이터 유출·비용 부담 ↓ |
| 표준화 | RAG·검색 튜토리얼의 사실상 표준 → 자료·예제가 풍부 |
한마디로: “유료 임베딩 API 안 쓰고, 공짜로 내 컴퓨터에서 돌리고 싶을 때 1순위.”
4. 어떻게 쓰는가? (How)
설치:
pip install sentence-transformers문장 → 벡터 → 유사도:
from sentence_transformers import SentenceTransformer, util
model = SentenceTransformer("all-MiniLM-L6-v2") # 처음 1회만 다운로드(~22MB)
sentences = ["강아지가 공원에서 뛴다", "개가 밖에서 달린다", "오늘 환율이 올랐다"]
emb = model.encode(sentences) # shape: (3, 384)
print(util.cos_sim(emb[0], emb[1])) # 0.7 (비슷)
print(util.cos_sim(emb[0], emb[2])) # 0.05 (무관)흐름은 단순합니다: 문장 → encode() → 벡터 → cos_sim() → 유사도 점수 → 정렬/판단.
5. 실제 사용 예 (도식)
예시 A — 시맨틱 검색: 키워드가 안 겹쳐도 의미로 찾기
일반 검색은 단어가 정확히 겹쳐야 찾지만, MiniLM은 의미로 찾습니다. 질문에 “환불”이라는 단어가 없어도 “환불 정책 안내” 문서를 찾아냅니다.
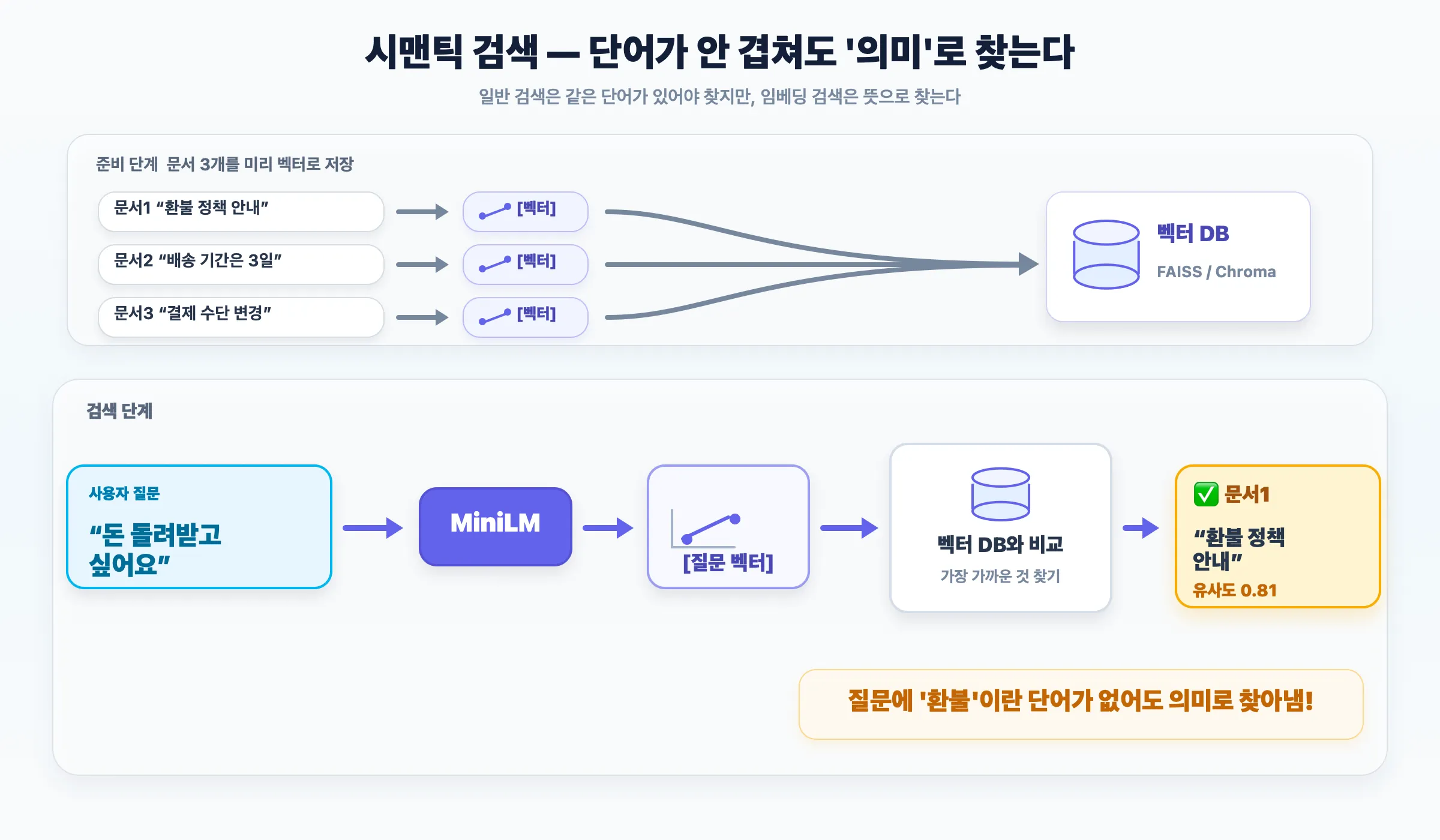
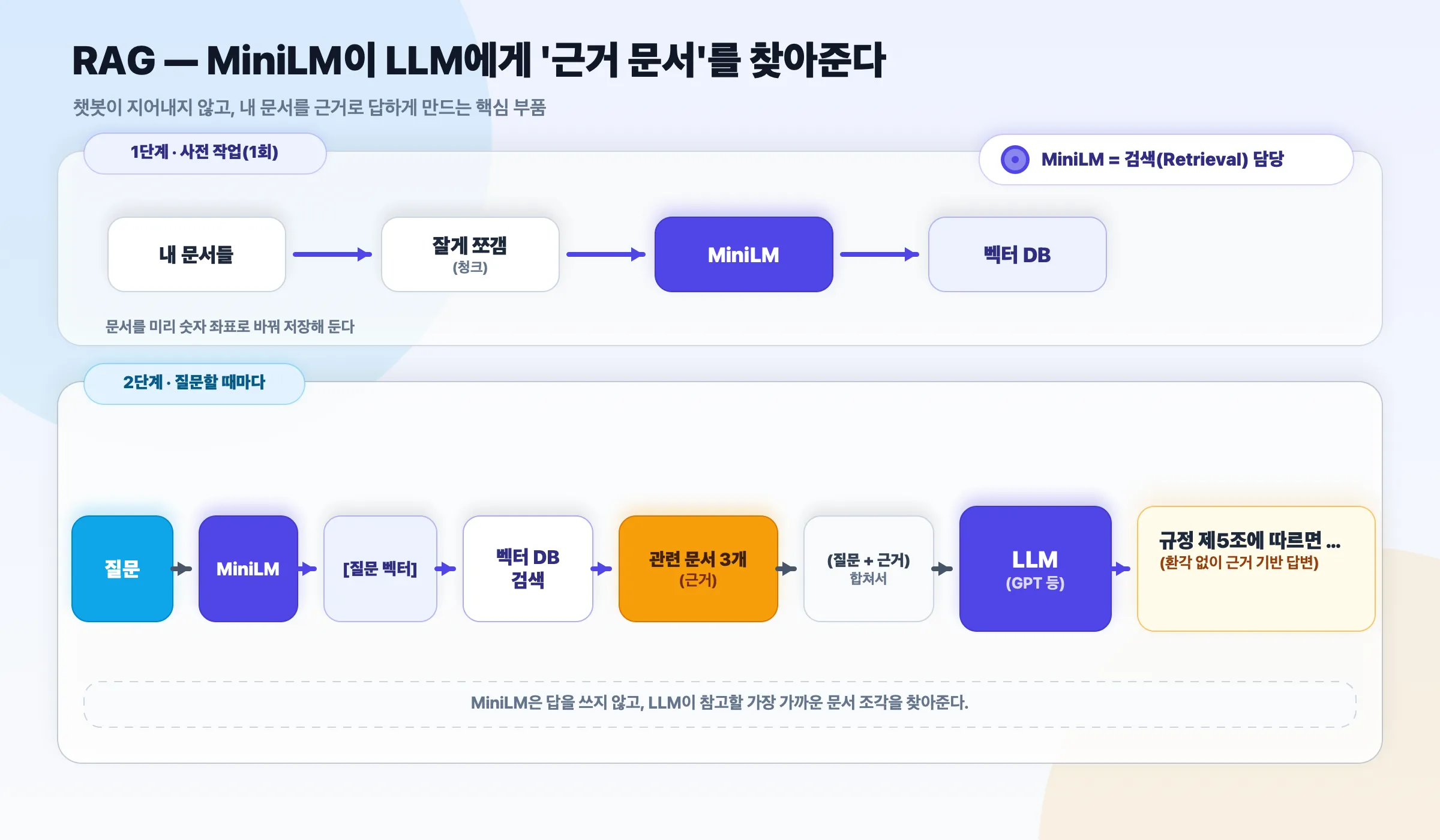
예시 B — RAG: 챗봇이 내 문서를 근거로 답하기
ChatGPT 같은 LLM에 “우리 회사 규정”을 근거로 답하게 만들 때 쓰는 핵심 부품입니다. MiniLM은 질문과 관련된 근거 문서를 찾아주는 검색(Retrieval) 을 담당하고, LLM은 그 근거를 바탕으로 답합니다. 덕분에 LLM이 헛소리(환각)를 덜 합니다.
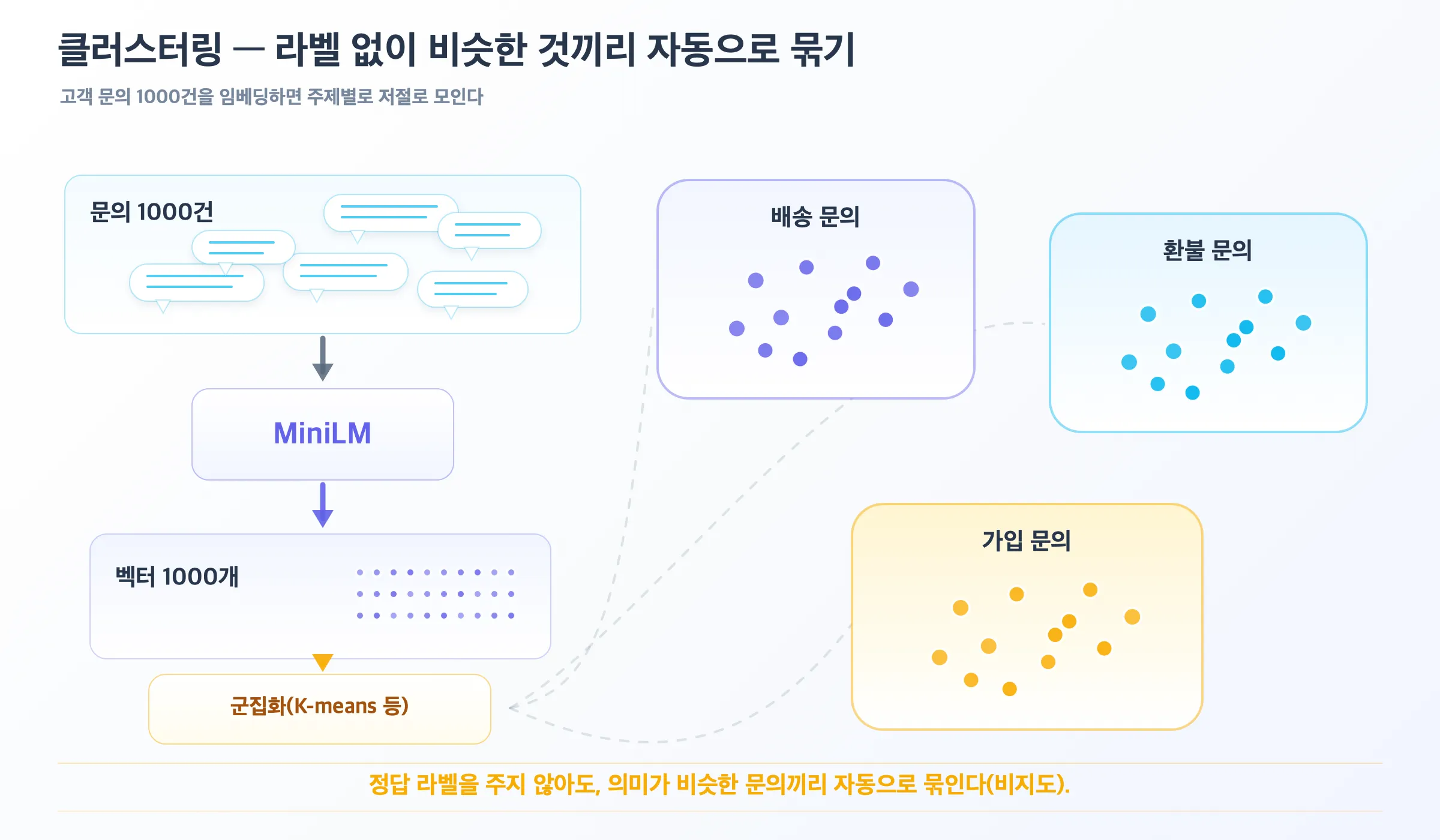
예시 C — 클러스터링: 비슷한 것끼리 자동 분류
정답 라벨을 주지 않아도, 문의 수천 건을 임베딩하면 의미가 비슷한 것끼리 저절로 묶입니다(비지도 학습).
6. 언제 어떤 모델을 쓸까
MiniLM이 만능은 아닙니다. 가벼움·속도와 정확도·품질은 트레이드오프입니다.

- 가볍고 빠르게, 공짜로 →
all-MiniLM-L6-v2 - 품질이 더 필요 →
all-mpnet-base-v2 - 한국어 비중이 크면 →
paraphrase-multilingual-MiniLM-L12-v2같은 다국어 버전 권장 (기본 L6-v2는 영어 중심)
7. 쓸 때 주의점
- 입력 256 토큰 초과 → 잘림. 긴 문서는 미리 청크(chunk)로 쪼개세요.
- 기본 모델은 영어 위주. 한국어가 많으면 multilingual 버전을 쓰세요.
- 벡터는 한 번만 만들고 저장. 매번 재계산하지 말고 벡터 DB에 캐싱하세요.
- 비교는 코사인 유사도. 정규화(normalize) 후 내적을 써도 동일합니다.
참고: 이름이 비슷한 “MiniLLM”은 다른 것
이름이 한 글자 다른 MiniLLM(L이 하나 더)은 전혀 다른 연구입니다. 생성형 LLM을 reverse KLD로 증류하는 기법으로, 여기서 다룬 임베딩용 MiniLM과는 목적·대상이 다릅니다. 혼동하지 마세요.
정리
- 문장 → MiniLM → 384차원 벡터 → 비교/검색/분류. “의미를 숫자로” 바꿔서 “의미로 일하게” 만드는 도구.
- 핵심 용도: ① 시맨틱 검색 ② RAG 챗봇 ③ 클러스터링 ④ 중복 탐지
- 핵심 장점: 작다 · 빠르다 · 공짜 · 로컬 실행