BERT, 쉽게 이해하기 — 문장을 '양방향으로 읽고 이해하는' 모델 (왜 action classifier에 쓸까)
2018년 구글 BERT가 무엇인지 101 수준으로 쉽게 풀고, 왜 대화형 에이전트의 action classifier(행동 분류)에 BERT가 잘 맞는지 그 이유를 그림으로 설명합니다.
“BERT가 뭐냐”고 하면 한마디로 문장을 깊이 “이해”하는 데 특화된 모델입니다. ChatGPT처럼 글을 새로 써내는 모델이 아니라, 주어진 문장의 뜻을 파악해 분류·검색·질의응답 같은 일을 잘하죠. 2018년 구글이 공개한 뒤 자연어처리(NLP)의 사실상 표준이 됐습니다. 이 글은 그림 위주로 쉽게 풀고, 마지막에 왜 대화형 에이전트의 “action classifier”에 BERT를 쓰는지까지 설명합니다.
1. 한 문장으로
BERT = 문장을 양쪽 문맥을 동시에 보며 “읽고 이해”하는 모델. 새 글을 쓰기보다 고르고 분류하는 데 강하다.
2. 이름 뜯어보기
BERT = Bidirectional Encoder Representations from Transformers.
- Transformer: 요즘 거의 모든 언어 모델의 바탕이 되는 신경망. 크게 인코더(읽고 이해하는 부분) 와 디코더(써내는 부분) 로 나뉩니다.
- Encoder: BERT는 이 중 인코더만 씁니다. 그래서 “읽고 이해”에 특화돼 있죠.
- Bidirectional(양방향): 문장을 왼쪽→오른쪽 한 방향이 아니라 양쪽을 동시에 봅니다.
- Representations: 문장(과 단어)을 의미가 담긴 벡터(숫자 묶음) 로 바꿔 표현합니다.
3. 핵심 아이디어 — 양방향 “빈칸 채우기”
예전 모델은 보통 왼쪽→오른쪽으로 다음 단어를 예측했습니다. BERT는 문장 중간을 가리고 양쪽 문맥으로 맞히게 배웁니다.
“나는 아침에 ___ 을 마셨다” → 앞(“아침에”)과 뒤(“마셨다”)를 모두 보고 “커피”라고 추측.
양쪽을 다 보기 때문에 문맥 이해가 깊습니다. 이게 “Bidirectional(양방향)“의 힘이에요.
4. 어떻게 배웠나 — 두 가지 사전학습
정답 라벨 없이 인터넷 텍스트(위키피디아 등)로 스스로 배웁니다(self-supervised). 두 가지 게임을 시킵니다.
- MLM (Masked Language Model): 단어의 약 15%를
[MASK]로 가리고 맞히기 → 단어·문맥 이해. - NSP (Next Sentence Prediction): 두 문장이 실제로 이어지는지 맞히기 → 문장 사이의 관계 이해.
그리고 두 단계로 씁니다.
- 사전학습(pre-training): 위 게임으로 대량 텍스트에서 “언어 일반 지식”을 익힙니다. (오래 걸리고 비싸지만, 구글이 한 번 해뒀습니다.)
- 미세조정(fine-tuning): 그 위에 작은 데이터로 특정 일(스팸 분류 등)만 살짝 더 학습 → 적은 데이터로도 좋은 성능이 납니다.
이 “한 번 크게 배워두고, 필요할 때 조금만 더 배운다”가 BERT가 퍼뜨린 패러다임입니다.
5. BERT가 제일 잘하는 일 = “고르기”
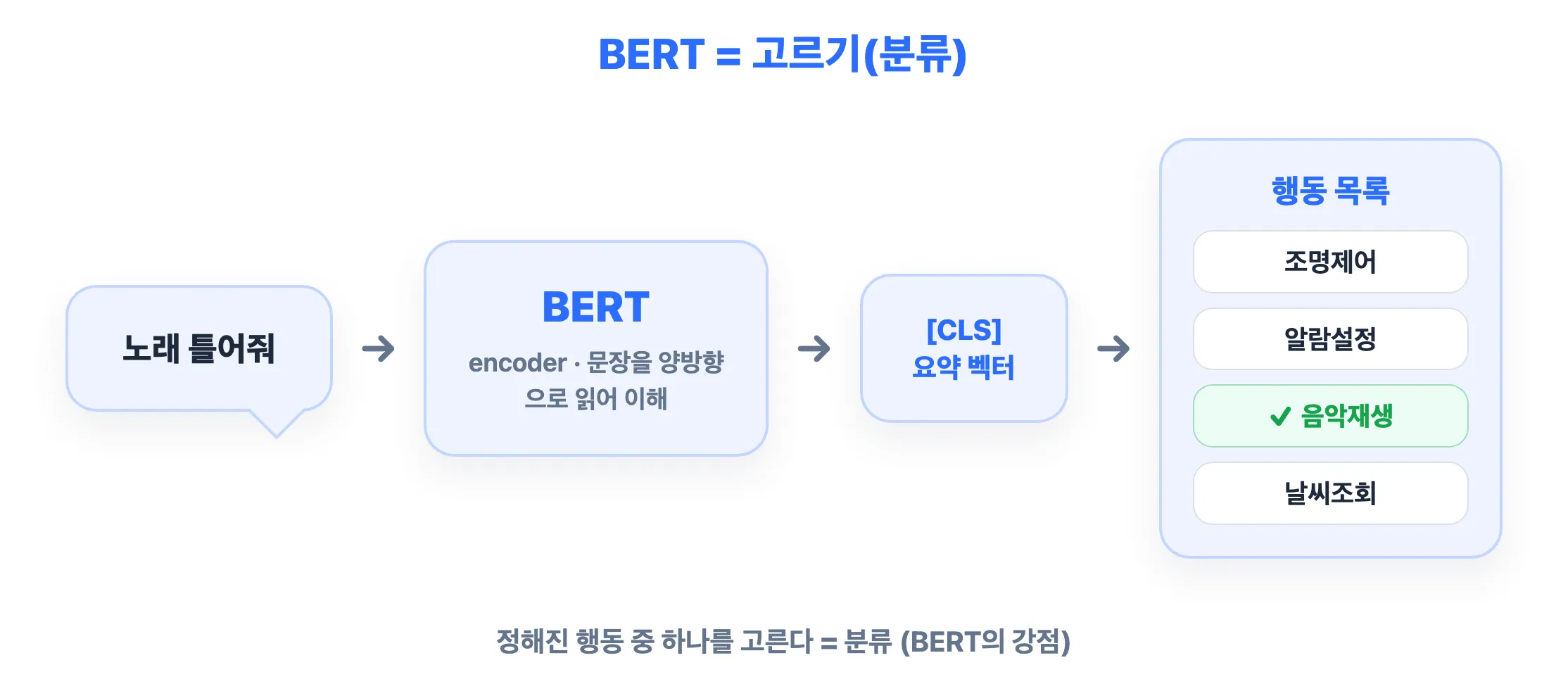
BERT는 문장 전체를 읽어, 맨 앞 특수 토큰 [CLS] 자리에 문장 전체의 뜻을 요약한 벡터 하나를 만듭니다. 그 벡터 위에 작은 분류기를 얹으면, 문장을 정해진 보기 중 하나로 분류할 수 있습니다.
- 감정 분석(긍정/부정), 스팸 판별, 주제 분류, 개체명 인식, 질의응답, 검색 랭킹 …
- 공통점: 정답이 “정해진 집합 안” 에 있고, 새 문장을 지어낼 필요가 없습니다.
6. 그래서 — 왜 action classifier에 BERT를 쓸까
대화형 에이전트(음성비서·챗봇)는 사용자의 말을 듣고 무슨 행동(action)을 할지 먼저 정해야 합니다. “불 꺼줘”, “내일 알람 맞춰줘”, “노래 틀어줘” → 각각 조명제어, 알람설정, 음악재생 같은 행동 분류(action classification, 흔히 intent 분류라고도 함) 입니다. (맨 위 그림이 바로 이 흐름이에요.)
이 일이 BERT에 딱 맞는 이유는 이렇습니다.
- 출력이 “정해진 보기 중 하나” 입니다. 에이전트가 할 수 있는 행동은 미리 정해진 목록(수십~수백 개)이에요. 새 문장을 지어낼 필요 없이 그중 하나만 고르면 되니, 전형적인 분류 문제입니다.
- BERT는 발화를 양방향으로 읽어
[CLS]벡터 하나로 요약한 뒤, 그 위 분류기로 행동 하나를 선택합니다. 디코더(생성기)가 필요 없으니 빠르고 가볍습니다. 에이전트는 응답이 빨라야 하므로 이게 큰 장점이에요. - 짧고 문맥에 기대는 말(“그거 취소”)도 양방향 이해 덕분에 잘 잡습니다.
- fine-tune이 쉬워서, 우리 서비스의 행동 목록에 맞춰 적은 데이터로도 높은 정확도를 냅니다.
한마디로, “여러 보기 중 하나 고르기”가 BERT의 홈그라운드라서 action classifier로 씁니다.
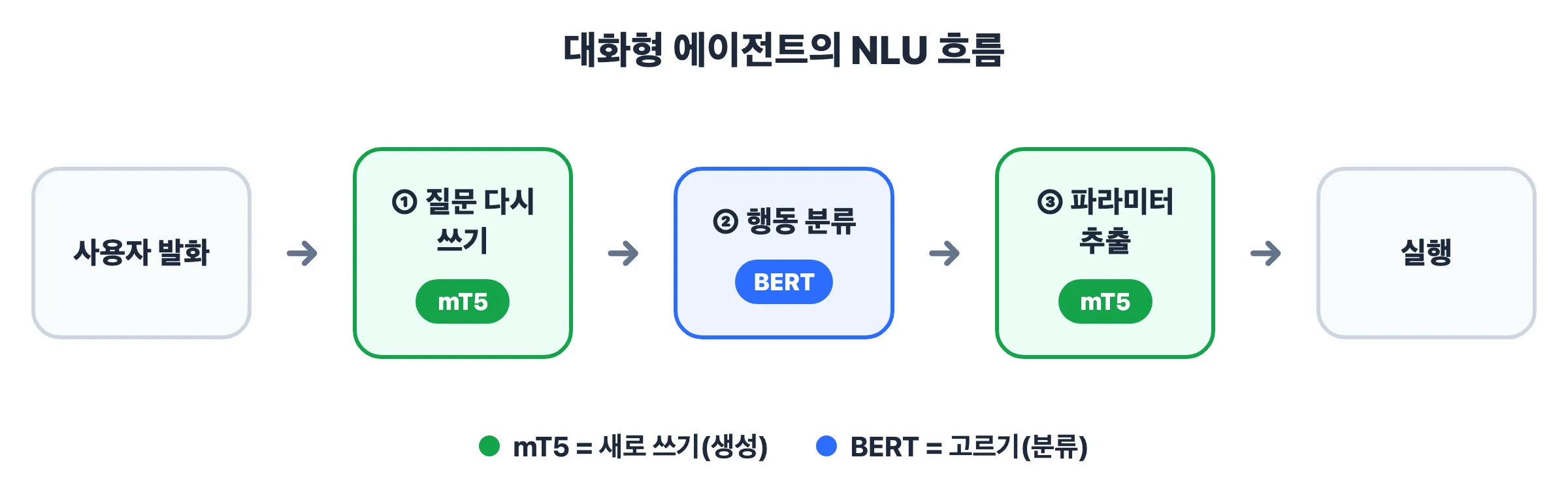
참고: 같은 발화에서 “언제·무엇을” 같은 세부 값을 뽑거나, 말을 다시 써주는 일은 원문에 없는 새 텍스트를 만들어내야 해서 BERT보다 mT5 같은 생성 모델이 낫습니다. (→ mT5 글에서 이어집니다.)
7. 크기
- BERT-base: 12층, 약 1.1억(110M) 파라미터
- BERT-large: 24층, 약 3.4억(340M) 파라미터
요즘 LLM(수백억~수천억)에 비하면 작지만, 분류 같은 일엔 이 정도가 빠르고 충분해서 지금도 현역으로 쓰입니다.
8. BERT가 약한 것
인코더만 있어서 긴 글을 새로 생성하는 데는 약합니다. 그건 디코더가 있는 모델의 몫이에요.
- BERT (encoder-only): 읽고 이해/분류 — “고르기”
- GPT (decoder-only): 이어서 생성 — “써내기”
- T5 / mT5 (encoder-decoder): 이해 + 생성 — “읽고 다시 쓰기”
그래서 실제 서비스에서는 이 모델들을 함께 씁니다. 예를 들어 대화형 에이전트의 NLU 흐름에서 BERT는 행동 분류를 맡고, mT5는 다시쓰기·파라미터 추출을 맡습니다.
정리
- BERT = 양방향으로 문장을 깊이 이해하는 encoder-only 모델 (2018, 구글)
- 빈칸 채우기(MLM) + 문장 잇기(NSP)로 사전학습 → fine-tune으로 특정 작업에 맞춤
- 강점은 “고르기”(분류·이해) → 그래서 에이전트의 action classifier에 적합 (정해진 행동 중 하나를 빠르고 정확하게 선택)
- 새 텍스트 생성은 약함 → 그건 mT5/GPT가 맡는다
참고 자료: BERT (Wikipedia), 원논문 Devlin et al., 2018, “BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding”.