IFP 뜯어보기 — '질문을 읽고 필요한 부분만 켜는' 모델 (Instruction-Following Pruning)
Apple의 Instruction-Following Pruning(arXiv 2501.02086)을 실제 동작 단계까지 도식으로 따라갑니다. Sparsity Predictor·SoftTopK·FFN 가지치기·2단계 학습, 그리고 입력이 정확히 무엇이고 언제 한 번 고르는가(멀티턴 아님)까지.
AFM 3 Core Advanced의 희소 구조 밑바탕인 IFP(Instruction-Following Pruning) 를, 컨셉만이 아니라 실제로 어떻게 동작하는지 단계별로 도식과 함께 따라갑니다. 원 논문은 arXiv 2501.02086 (Apple · UC Santa Barbara)입니다.
1. 핵심 아이디어 — 질문을 보고 필요한 부분만 켠다
큰 모델은 강력하지만, 한 작업에 전부 다 필요하진 않습니다. IFP는 프롬프트를 먼저 읽고, 그 일에 필요한 FFN 차원만 켜서 입력마다 다른 슬림 서브넷을 만듭니다. 모든 입력에 같은 마스크를 쓰는 정적 가지치기와 달리, “입력마다 다른” 동적 마스크가 핵심입니다.
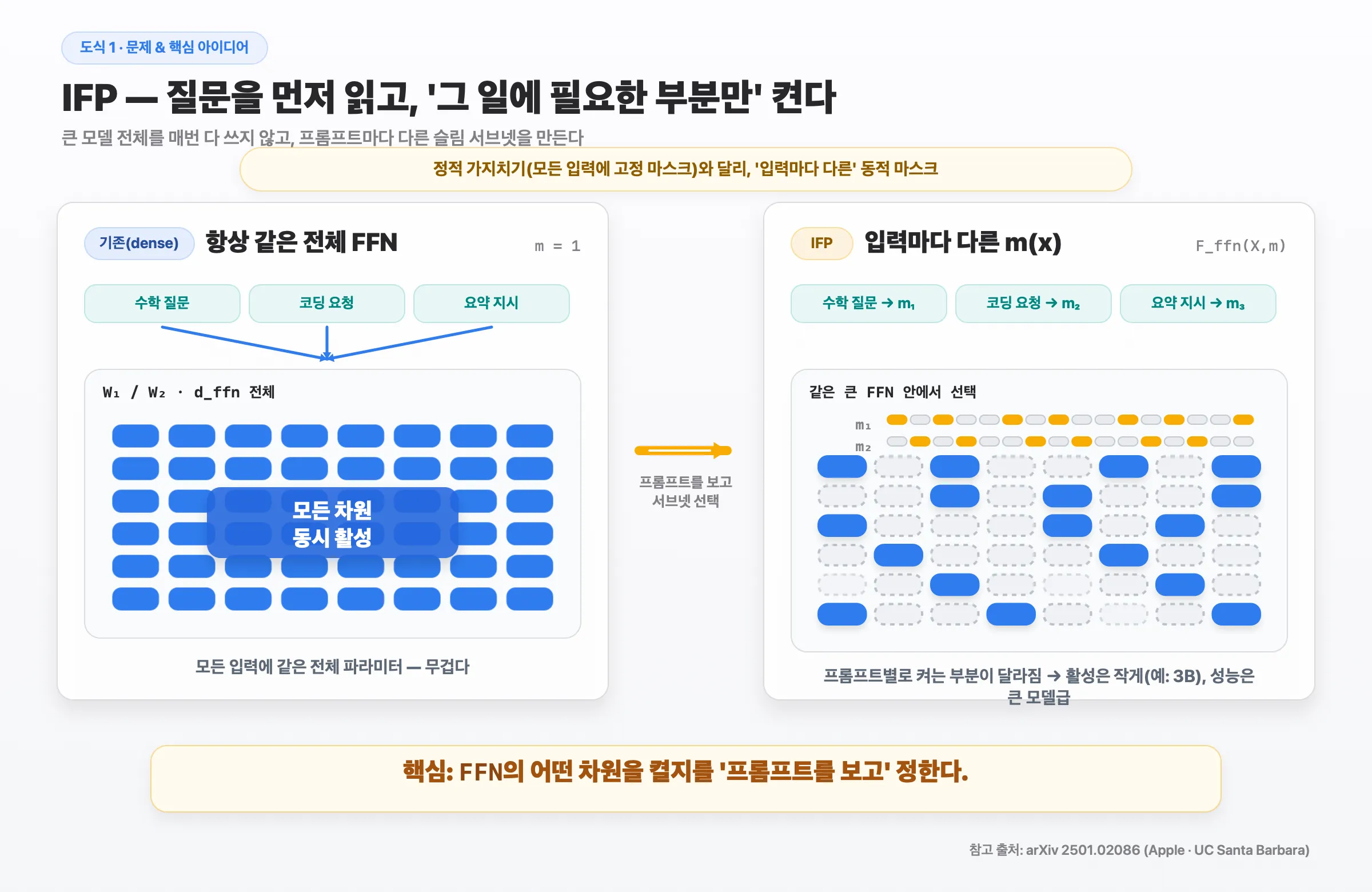
2. 전체 흐름 (추론 시)
실사용에서 한 번에 일어나는 경로입니다: 프롬프트 → 점수 → 선택 → 가지치기 → 생성.

마스크는 응답 생성 “전”에 한 번 정해지고, 디코딩 내내 고정됩니다(토큰마다 다시 고르지 않음). 점수를 내는 Sparsity Predictor는 큰 LLM과 별개의 작은 모델입니다.
3. Sparsity Predictor — 프롬프트를 점수로
약 302M 크기의 작은 LLM 백본이 프롬프트를 읽습니다.
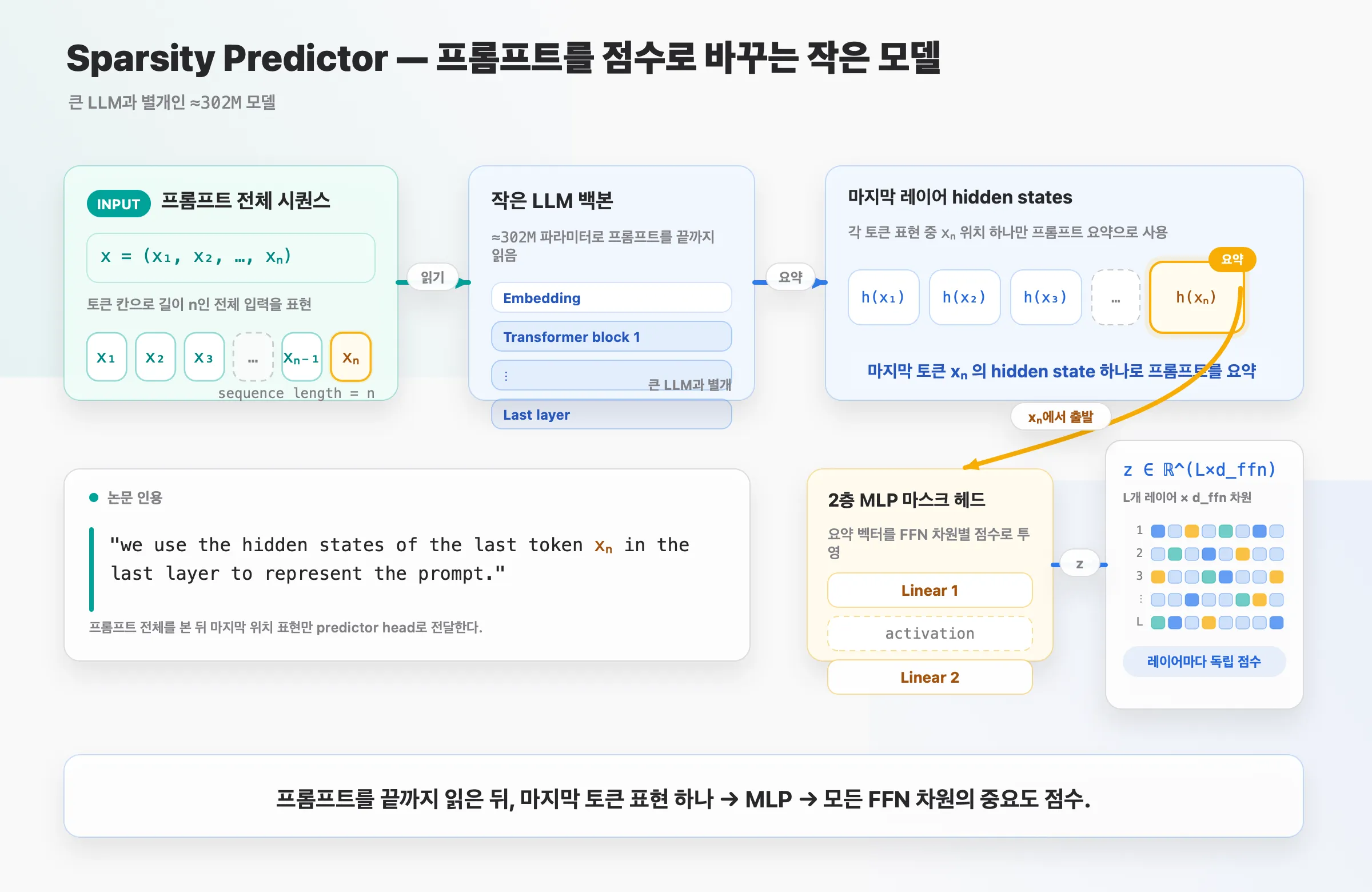
- 입력: 프롬프트 전체 시퀀스
x = (x₁, …, xₙ). - 논문 그대로: “we use the hidden states of the last token xₙ in the last layer to represent the prompt.” → 마지막 토큰 하나의 표현으로 프롬프트를 요약.
- 그 표현을 2층 MLP 마스크 헤드에 넣어 점수
z ∈ ℝ^(L×d_ffn)를 출력. 레이어마다 독립적인 점수입니다.
4. ‘입력’이 정확히 무엇이고, 언제 한 번 고르나 (멀티턴 아님)
가장 오해하기 쉬운 지점이라 따로 짚습니다.

- 입력 = 사용자 프롬프트(지시문) 전체 토큰열
x₁…xₙ. 한 문장이 아니라, 요청 덩어리 전체(여러 문장·few-shot 포함 가능)입니다. - 멀티턴 대화여도 누적해서 보지 않습니다. 논문: “For multi-turn conversational data, we only use the first human message as the prompt for sub-network selection.” → 첫 사용자 메시지 하나로 서브넷을 고릅니다.
- 선택 시점: 프롬프트를 끝까지 읽은 시점(마지막 토큰)에서 한 번 → 응답 생성 전에 마스크 확정 → 디코딩 내내 고정. 생성 중인 토큰은 보지 않습니다. (MoE/contextual sparsity가 토큰마다 다시 고르는 것과 다름.)
- 논문이 정하지 않은 것(정직하게): 시스템 프롬프트 포함 여부, 길이 한계, 문맥 히스토리 포함 여부는 미명시. (
prompt·instruction·task description을 혼용)
한 줄: 추론에선 “첫 프롬프트 하나 → 마스크 하나 → 끝까지 고정”. (학습 때만 청크별로 갱신 — 8번 참고)
5. SoftTopK — 점수를 ‘미분 가능한’ 마스크로
점수에서 상위만 켜되, 학습으로 좋은 선택을 배우려면 그 선택이 미분 가능해야 합니다.
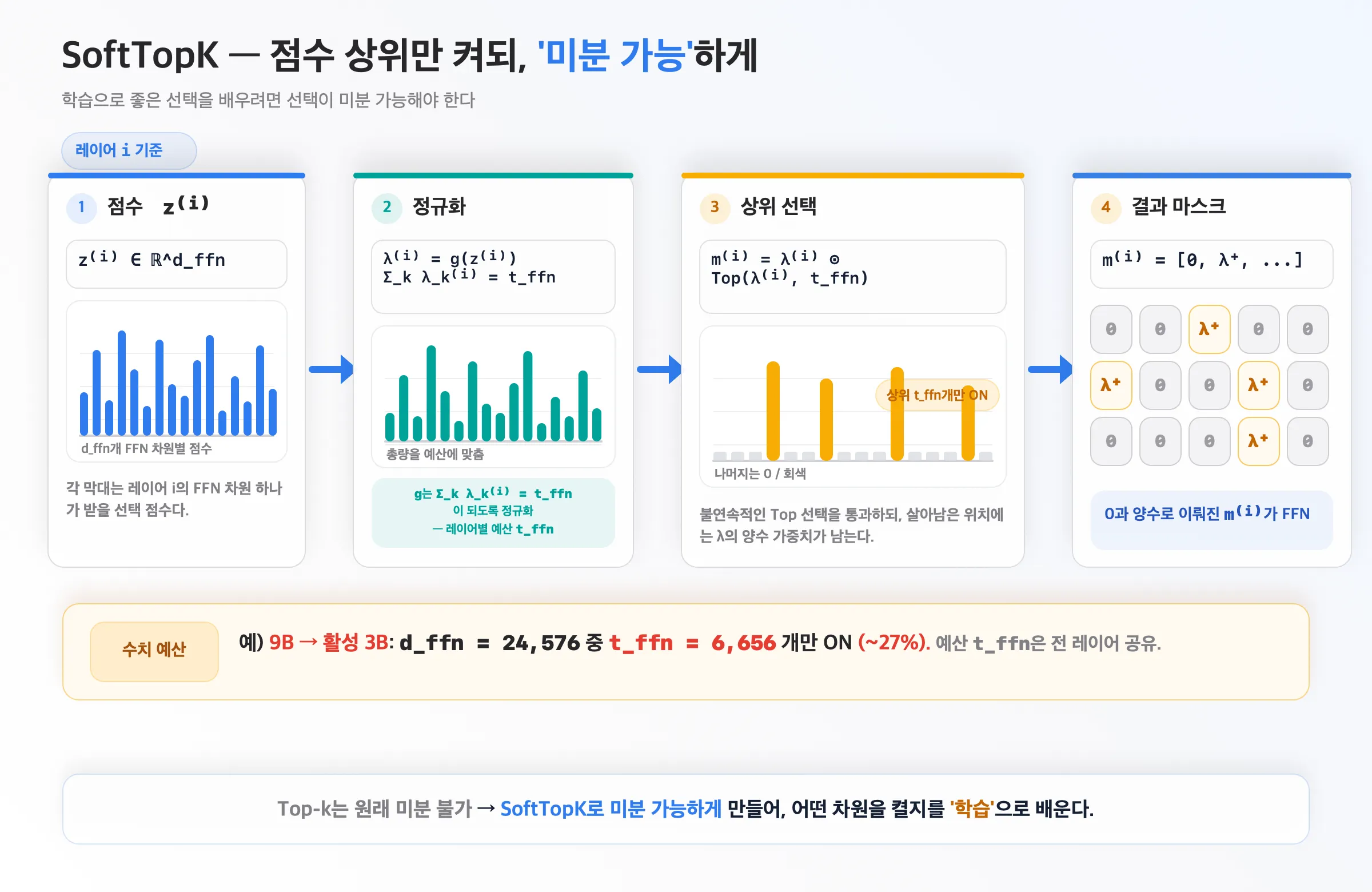
레이어 i에 대해:
λ⁽ⁱ⁾ = g(z⁽ⁱ⁾)—g는Σₖ λₖ⁽ⁱ⁾ = t_ffn이 되도록 정규화(레이어별 예산t_ffn).m⁽ⁱ⁾ = λ⁽ⁱ⁾ ⊙ Top(λ⁽ⁱ⁾, t_ffn)— 상위t_ffn개만 남기는 마스크.
예) 9B를 활성 3B로: d_ffn = 24,576 중 t_ffn = 6,656개만 ON(~27%), 예산은 전 레이어 공유. Top-k는 원래 미분 불가라 SoftTopK로 미분 가능하게 만들어 “어떤 차원을 켤지”를 학습합니다.
6. FFN 가지치기 — W₁의 열, W₂의 행
마스크는 FFN 중간 활성에 곱해집니다.
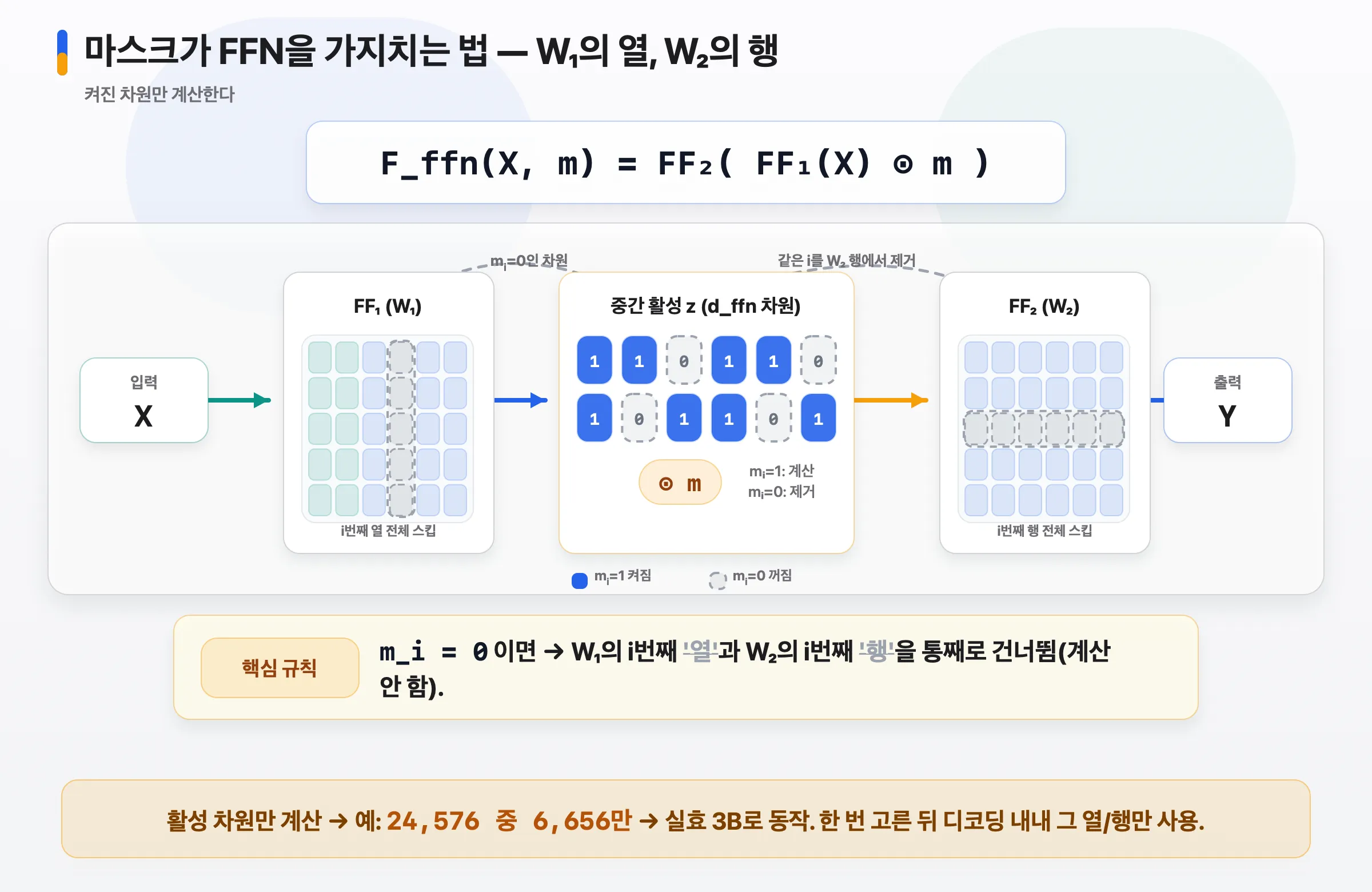
F_ffn(X, m) = FF₂( FF₁(X) ⊙ m )m_i = 0이면W₁의 i번째 열과W₂의 i번째 행을 통째로 건너뜁니다(계산 안 함).- 그래서 활성 차원만 계산 → 실효 3B로 동작. 한 번 고른 그 열/행을 디코딩 내내 씁니다.
7. 왜 빠른가 — ‘한 번 고르고 고정’ vs MoE
같은 희소성이라도 하드웨어에서 다르게 동작합니다.
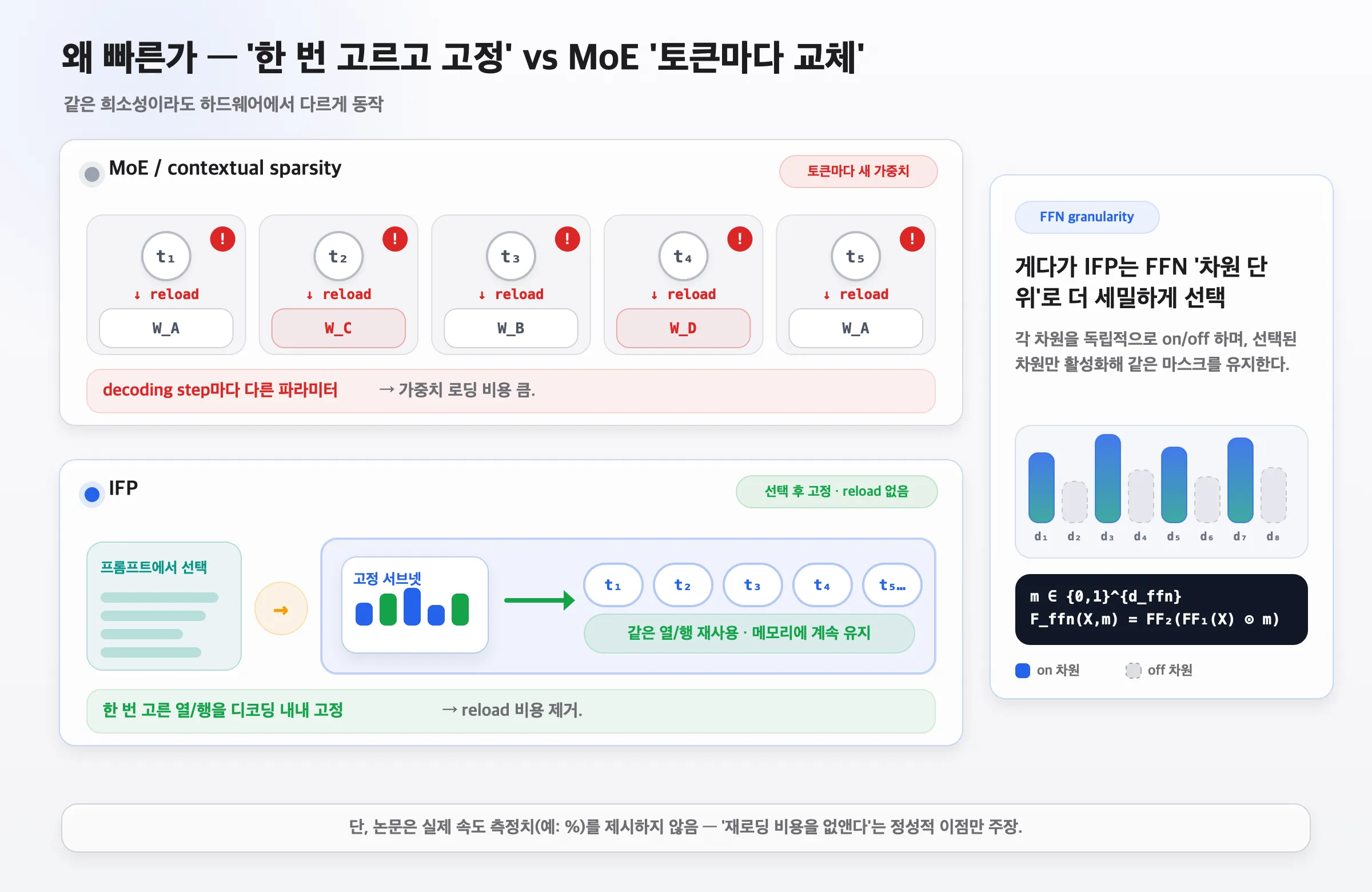
- MoE/contextual sparsity: 토큰마다 다른 파라미터를 불러옴 → 가중치 로딩 비용 큼.
- IFP: 프롬프트에서 한 번 선택 → 이후 토큰 전부 같은 서브넷 재사용 → 재로딩 비용 제거. 게다가 FFN 차원 단위로 더 세밀하게 on/off.
단, 논문은 실제 속도 측정치(%)를 제시하지 않습니다. “재로딩 비용을 없앤다”는 정성적 이점만 주장합니다.
8. 학습 ① — Continued pre-training (청크 방식)
predictor가 “문맥에 맞는 서브넷 고르기”를 라벨 없이 배우는 단계입니다.
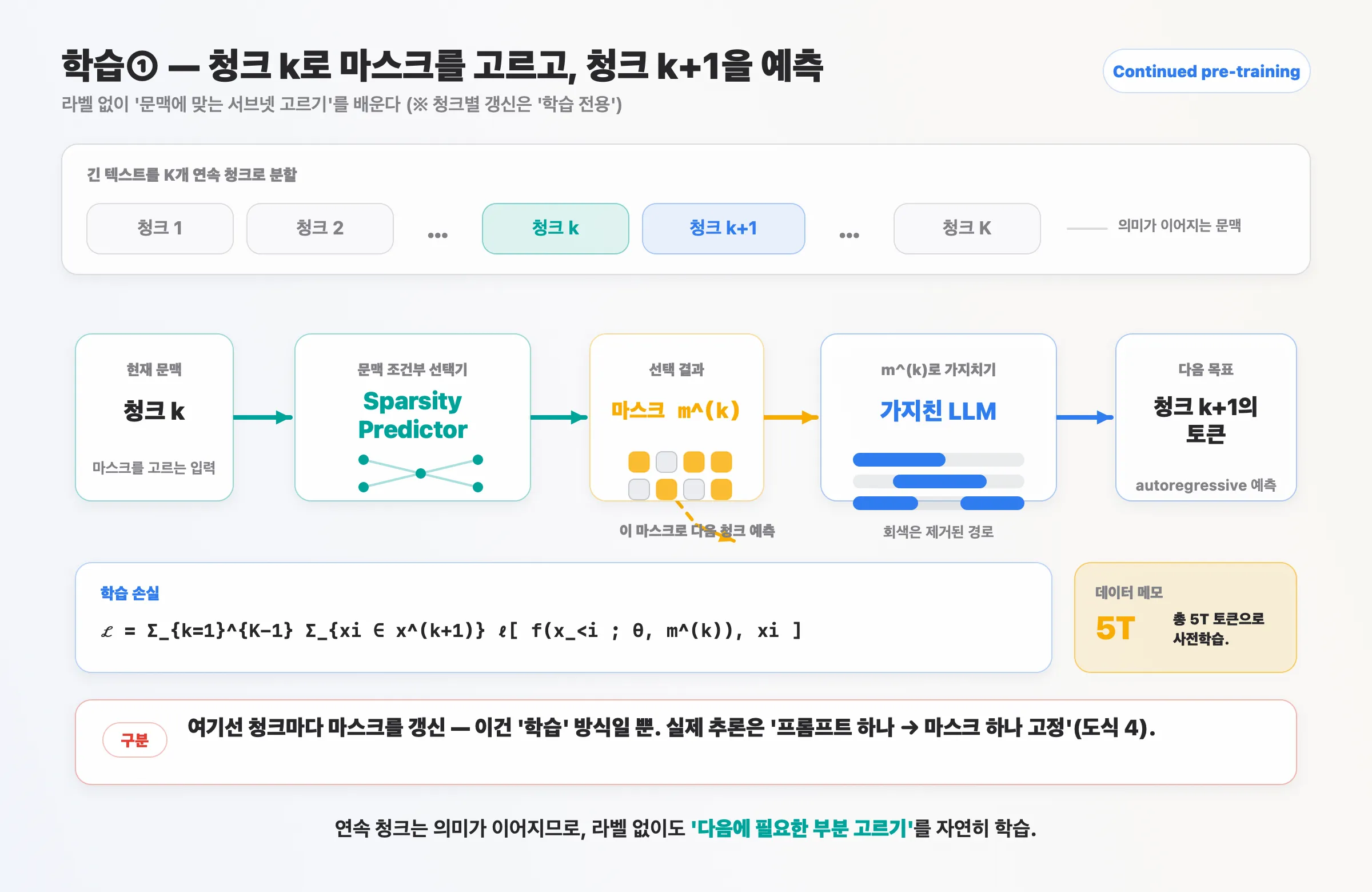
- 텍스트를 K개 연속 청크로 쪼개, 청크
k의 마스크m^(k)로 청크k+1의 토큰을 예측. - 손실:
ℒ = Σ_{k=1}^{K-1} Σ_{xᵢ ∈ x^(k+1)} ℓ[ f(x_{<i}; θ, m^(k)), xᵢ ], 총 5T 토큰. - 연속 청크는 의미가 이어지므로 라벨 없이도 “다음에 필요한 부분 고르기”를 학습합니다.
주의: 여기서 청크마다 마스크를 갱신하는 건 “학습” 방식일 뿐, 실제 추론은 4번처럼 “프롬프트 하나 → 마스크 하나 고정”입니다.
9. 학습 ② — SFT + 공동 최적화
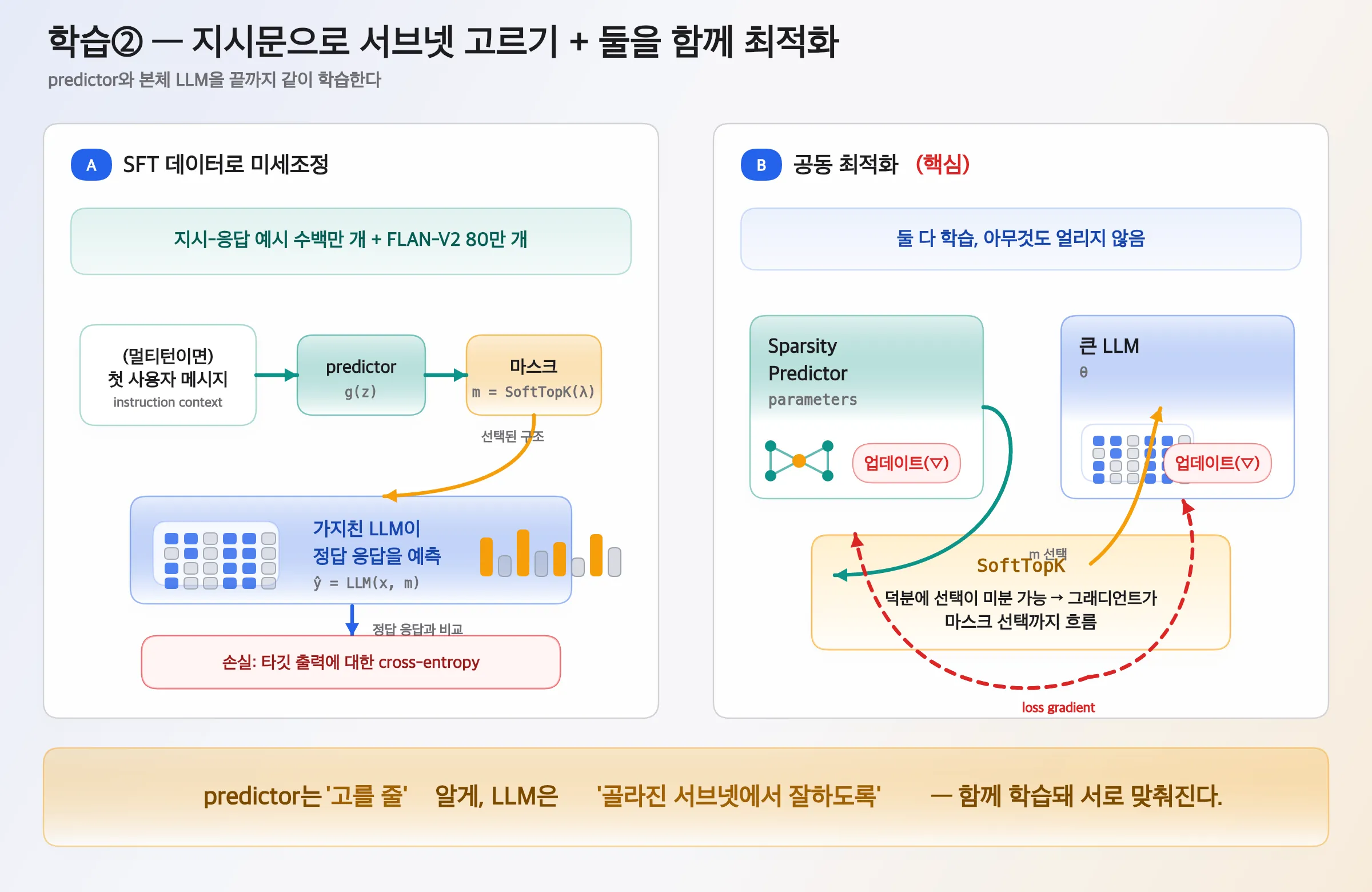
- SFT: 지시-응답 예시 수백만 개 + FLAN-V2 80만 개. (멀티턴이면) 첫 사용자 메시지로 마스크를 고르고, 가지친 LLM이 정답 응답을 예측(cross-entropy).
- 공동 최적화: Sparsity Predictor와 본체 LLM
θ를 둘 다 업데이트(아무것도 얼리지 않음). SoftTopK 덕에 그래디언트가 마스크 선택까지 흘러, predictor는 “고를 줄” 알고 LLM은 “골라진 서브넷에서 잘하도록” 서로 맞춰집니다.
10. 결과 — 활성 3B로 9B급에 근접
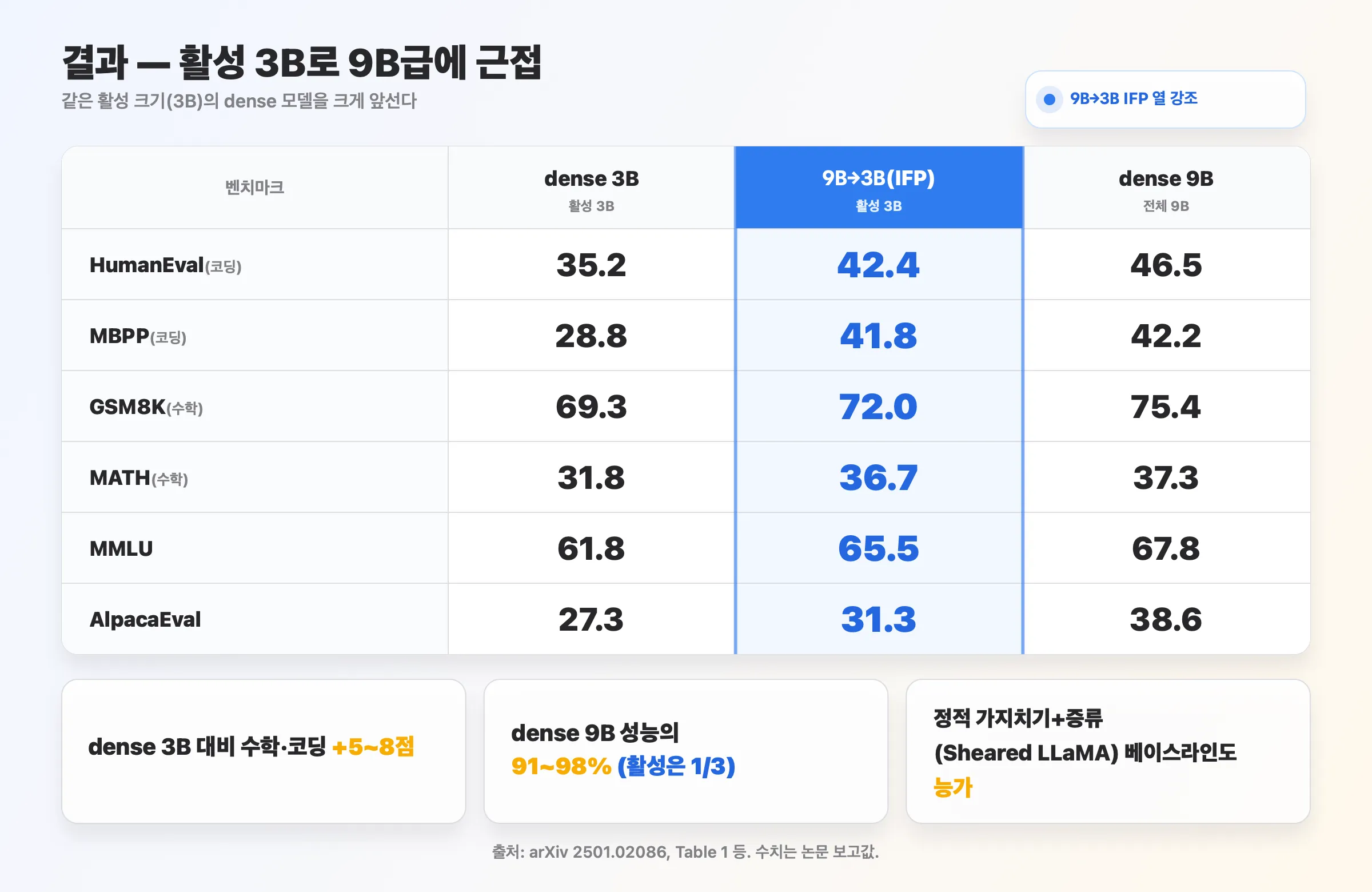
| dense 3B | 9B→3B (IFP) | dense 9B | |
|---|---|---|---|
| HumanEval | 35.2 | 42.4 | 46.5 |
| MBPP | 28.8 | 41.8 | 42.2 |
| GSM8K | 69.3 | 72.0 | 75.4 |
| MATH | 31.8 | 36.7 | 37.3 |
| MMLU | 61.8 | 65.5 | 67.8 |
| AlpacaEval | 27.3 | 31.3 | 38.6 |
- dense 3B 대비 수학·코딩 +5~8점.
- dense 9B 성능의 91~98%(활성은 1/3).
- 정적 가지치기 + 증류(Sheared LLaMA) 베이스라인도 능가.
정리
- 추론: 프롬프트(첫 사용자 메시지) 전체를 읽고 → 마지막 토큰으로 요약 → 점수 → SoftTopK로 마스크 한 번 확정 → FFN의 일부 열/행만 켜서 디코딩 내내 고정.
- 학습: 청크 기반 사전학습으로 “고르는 법”을 배우고, SFT에서 predictor와 LLM을 함께 최적화.
- 효과: 활성 3B로 dense 9B의 9할 이상을 내고, 같은 크기 dense 3B를 크게 앞선다. MoE와 달리 토큰별 재로딩이 없다(단 속도 측정치는 논문에 없음).
출처
- Instruction-Following Pruning for Large Language Models (arXiv 2501.02086) — 원 논문 (Apple · UC Santa Barbara)
- AFM 3 Core Advanced 뜯어보기 — IFP가 실제 제품에 적용된 맥락