아이폰에서 20B 모델이 도는 법 — Apple AFM 3 Core Advanced 뜯어보기
Apple 3세대 파운데이션 모델의 최상위 온디바이스 모델 AFM 3 Core Advanced. IFP(Instruction-Following Pruning) 동작 원리, MoE 라우팅, Private Cloud Compute와의 분담을 도식으로 정리합니다.
2026년 6월, Apple이 3세대 파운데이션 모델(AFM 3)을 공개했습니다. 그중 가장 눈에 띄는 건 AFM 3 Core Advanced — A19 Pro·M5급 칩이 있어야 “잠금 해제”되는, 20B 파라미터 희소(sparse) 온디바이스 모델입니다. 폰 메모리로는 다 못 올리는 20B를 어떻게 기기 안에서 굴릴까요. 핵심은 IFP, MoE 라우팅, 그리고 무거운 일을 넘기는 Private Cloud Compute입니다. 하나씩 뜯어봅니다.
0. 먼저 전체 지도 — AFM 3는 5종 패밀리
AFM 3는 한 개 모델이 아니라 5종으로 구성된 3단 체계입니다.
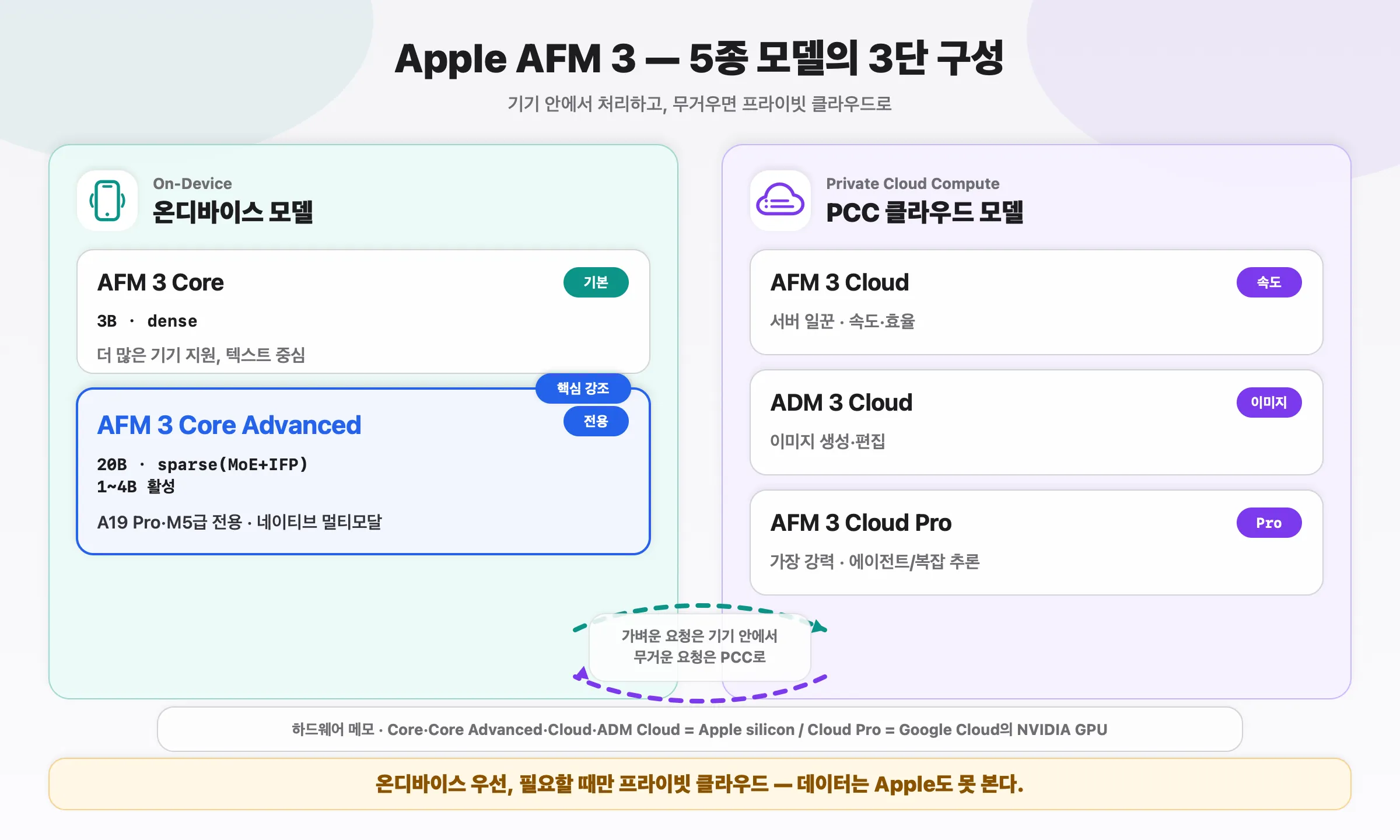
온디바이스 2종
- AFM 3 Core — 3B dense 모델. 더 많은 기기에서 돌아가는 기본기.
- AFM 3 Core Advanced — 20B sparse(MoE+IFP), 요청마다 1~4B만 활성. 네이티브 멀티모달. 가장 강력한 Apple silicon(A19 Pro·M5급) 전용.
Private Cloud Compute(서버) 3종
- AFM 3 Cloud — 속도·효율 중심의 서버 일꾼.
- ADM 3 Cloud — 이미지 생성·편집 전용.
- AFM 3 Cloud Pro — 가장 강력. 에이전트형 도구 사용·복잡한 추론 담당.
하드웨어: Core·Core Advanced·Cloud·ADM Cloud는 Apple silicon, 가장 무거운 Cloud Pro만 Google Cloud의 NVIDIA GPU에서 돕니다(둘 다 PCC 보안 안에서).
1. IFP — 프롬프트를 보고 ‘필요한 부분만’ 켠다
AFM 3 Core Advanced의 희소 구조는 Apple이 2025년 발표한 IFP(Instruction-Following Pruning, 지시 따르기 가지치기) 위에 세워졌습니다. 한마디로 “입력(지시문)마다 다른 부분을 켜는 동적 가지치기” 입니다.
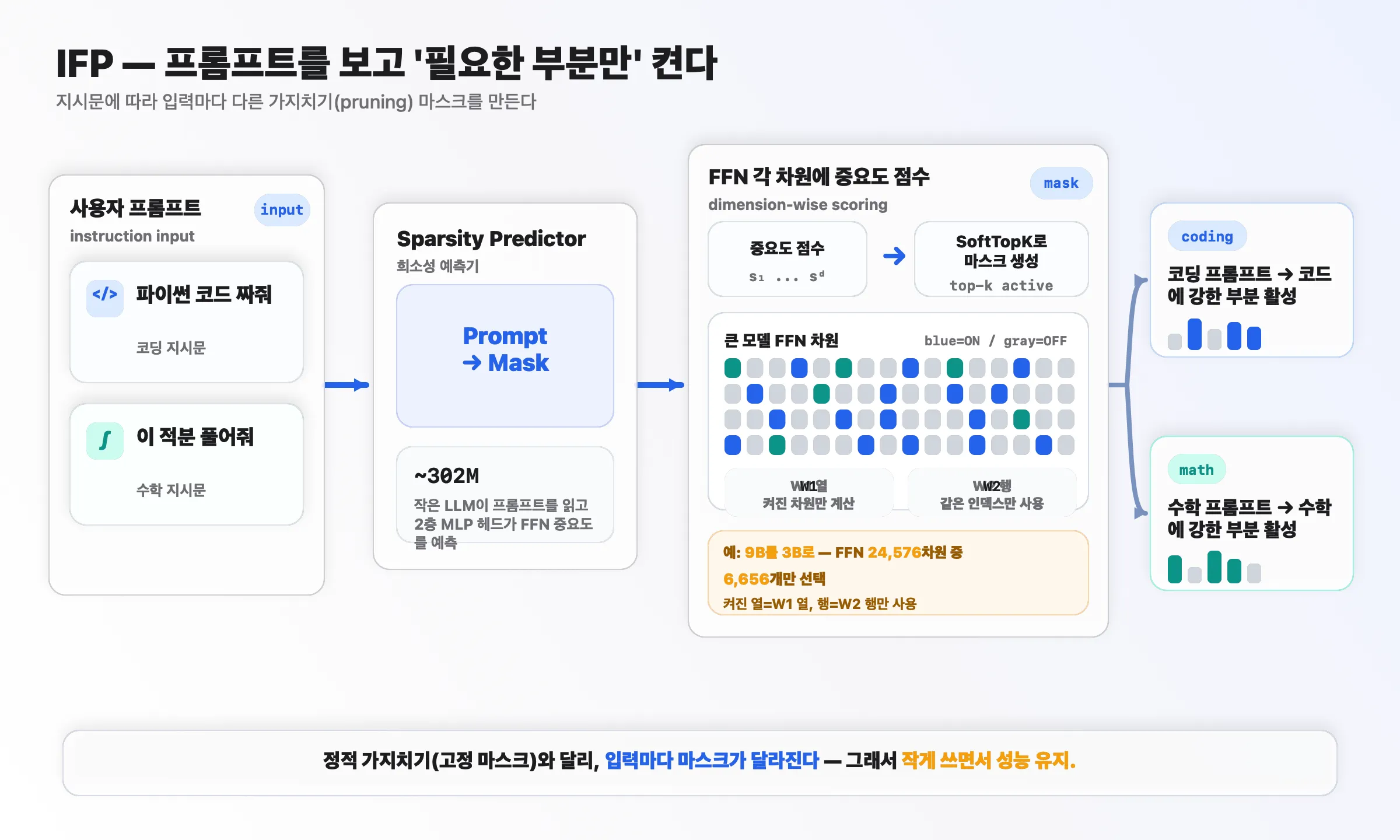
기존 정적 가지치기는 모든 입력에 같은 고정 마스크를 씁니다. IFP는 다릅니다.
- Sparsity Predictor(희소성 예측기) — 약 302M 크기의 작은 LLM + 2층 MLP 헤드. 사용자 프롬프트를 먼저 읽고, 마지막 토큰의 hidden state로 프롬프트를 요약합니다.
- FFN 차원별 중요도 점수 — 각 feed-forward(FFN) 레이어의 행·열마다 “이 입력에 얼마나 중요한가” 점수를 매깁니다.
- SoftTopK로 마스크 생성 — 점수 상위만 남기는 마스크를 만듭니다. 예를 들어 9B를 3B로 줄일 때, FFN 24,576차원 중 6,656개만 선택합니다. (켜진 열 =
W1의 열, 켜진 행 =W2의 행만 사용) - 입력별로 다른 활성 — 코딩 프롬프트면 코드에 강한 부분이, 수학 프롬프트면 수학에 강한 부분이 켜집니다.
핵심은 한 번 고르면 그 파라미터를 고정한다는 점입니다(토큰마다 갈아끼우는 MoE와 다름) — 그래서 reload 비용이 없습니다.
논문 결과(6B/9B/12B를 3B로 가지치기 → dense 3B와 비교):
- HumanEval(코딩) 41.0% vs 35.2%, GSM8K(수학) 72.2% vs 69.3%, MMLU 63.1% vs 61.8%
- 9B를 3B로 줄여도 dense 9B에 근접. 보도 기준 생성 시간 40%+ 단축.
2. MoE 라우팅 — 항상 켜진 전문가 + 필요할 때 부르는 전문가
20B 중 1~4B만 쓰는 실제 구조는 MoE(Mixture of Experts) 입니다. 다만 모바일에 맞게 변형했습니다.
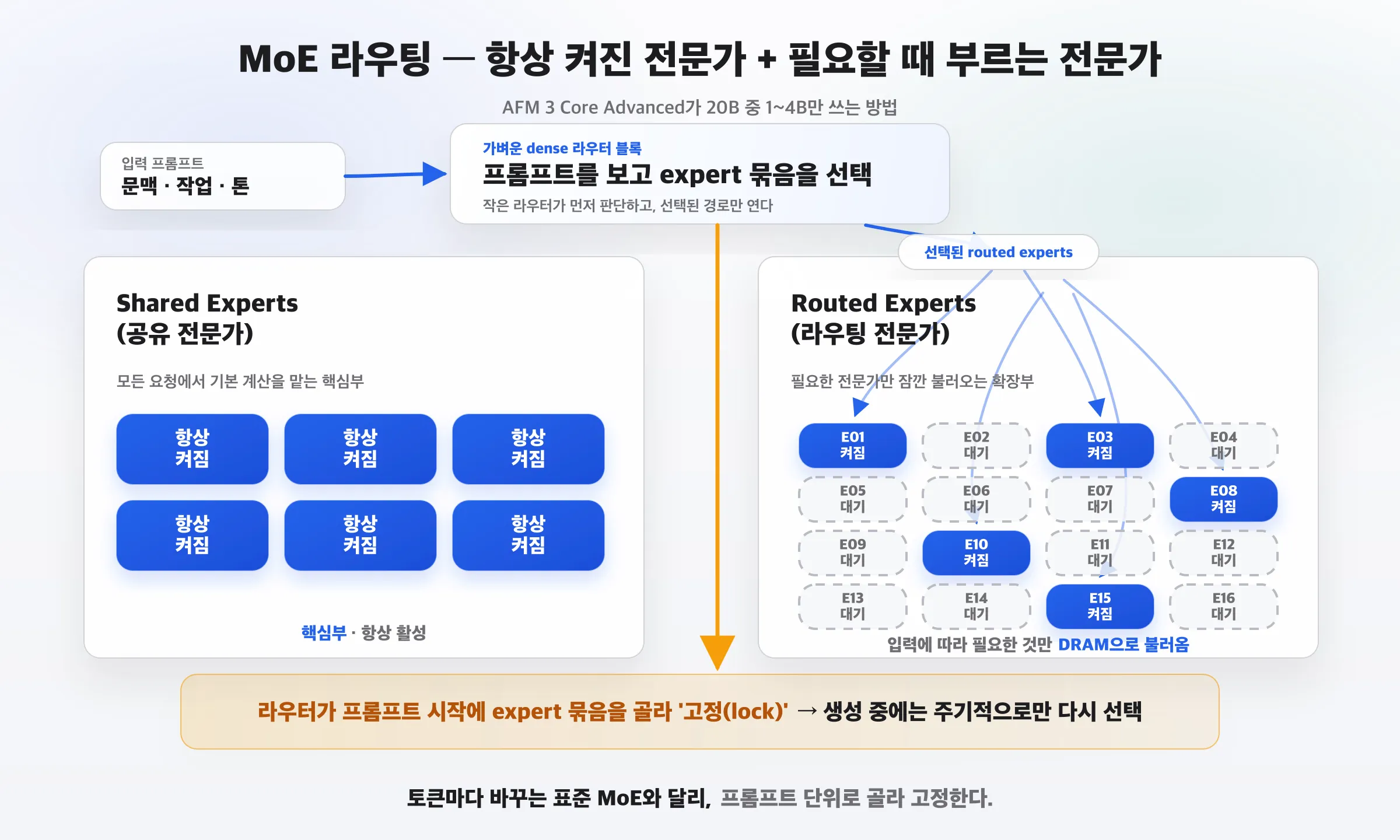
- Shared Experts(공유 전문가) — 비중이 높고 항상 켜져 있는 핵심부.
- Routed Experts(라우팅 전문가) — 입력에 따라 필요한 것만 DRAM으로 불러오는 부분.
- 가벼운 dense 라우터 블록이 프롬프트를 보고 어떤 routed expert를 켤지 고릅니다.
가장 중요한 트릭: 라우터가 프롬프트 시작에 expert 묶음을 한 번 골라 고정(lock)하고, 생성 중에는 주기적으로만 다시 고릅니다. 토큰마다 바꾸는 표준 MoE와 결정적으로 다른 지점입니다.
3. 왜 ‘프롬프트 단위’인가 — 메모리의 속도 벽
표준 MoE는 토큰마다 다른 전문가를 불러옵니다. 폰에서는 이게 안 됩니다.

- 20B 전체는 NAND 플래시(저장) 에 둡니다. 용량은 크지만 느립니다.
- 활성 1~4B만 DRAM(통합 메모리) 에 올려 Neural Engine/GPU로 추론합니다.
- 문제는 NAND → DRAM 대역폭이 느려서, 토큰마다 weight를 갈아끼우면 매번 멈춥니다.
그래서 AFM은 프롬프트 시작에 한 번 선택→고정하고 생성 내내 같은 weight를 재사용합니다. 플래시↔메모리 이동을 최소화해, 폰에서도 20B급을 굴릴 수 있게 만든 핵심입니다.
4. Private Cloud Compute와의 분담
온디바이스가 만능은 아닙니다. 무겁거나 복잡한 일은 Private Cloud Compute(PCC) 로 넘깁니다.

- 가볍고 빠른 일 → 온디바이스 (
AFM 3 Core,AFM 3 Core Advanced): 오프라인에서도 즉각 응답, 데이터가 기기 밖으로 안 나감. - 무겁거나 복잡한 일 → PCC (
AFM 3 Cloud,ADM 3 Cloud,AFM 3 Cloud Pro): 큰 추론·이미지·에이전트 작업.
PCC의 핵심은 프라이버시입니다. 기기 수준의 보안을 클라우드까지 확장해, 보낸 개인 데이터는 누구도(애플조차) 접근할 수 없고, 그 사실을 외부에서 검증할 수 있게 설계했습니다. Apple은 사용자의 사적 데이터·상호작용을 모델 학습에 쓰지 않습니다. (참고: AFM 3 Cloud Pro는 텍스트 응답 만족도에서 AFM 3 Cloud보다 약 10% 높다고 합니다.)
정리
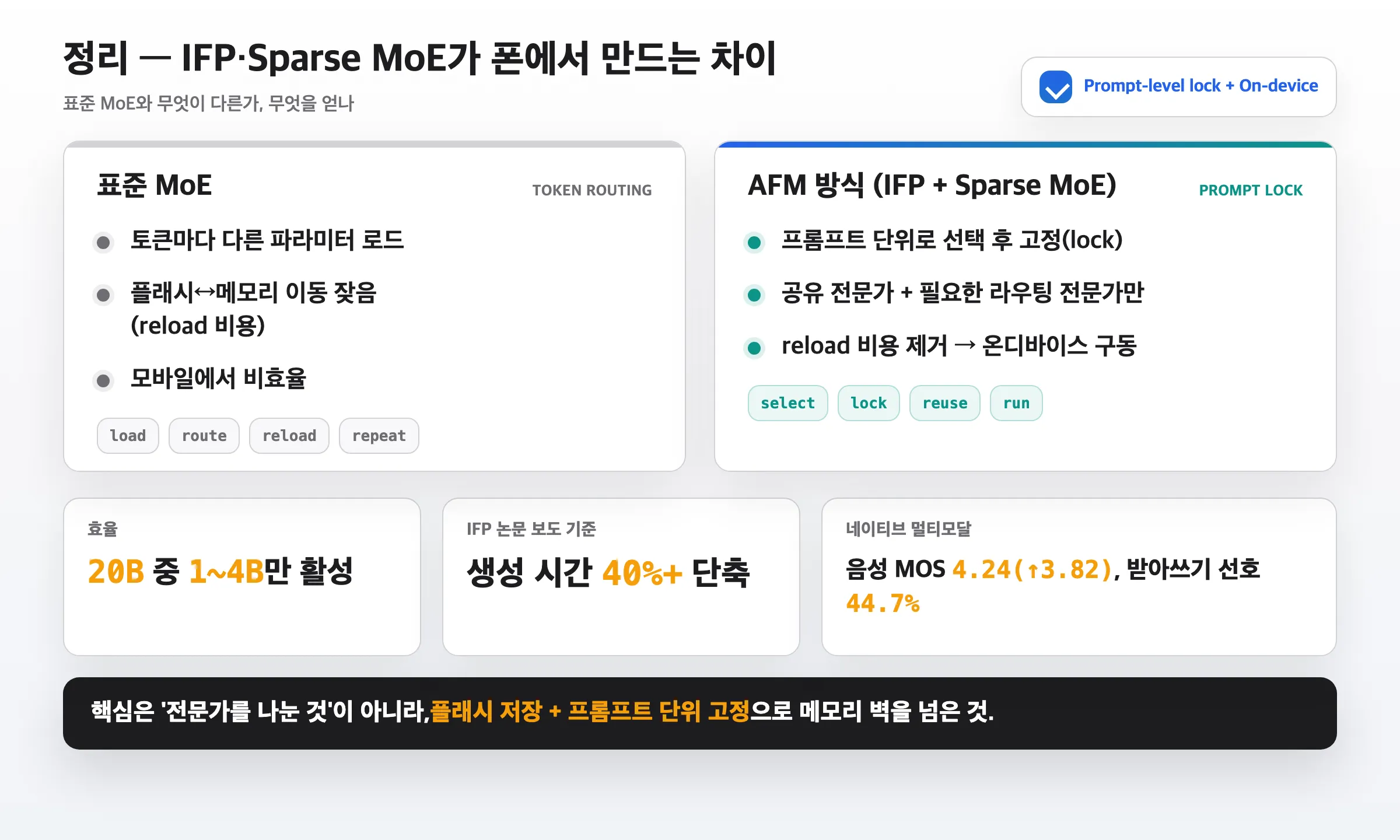
- AFM 3 Core Advanced = 20B 희소 온디바이스 모델. IFP + MoE로 요청마다 1~4B만 활성.
- IFP: 프롬프트를 읽는 희소성 예측기가 입력별 마스크를 만들어 필요한 FFN 차원만 켠다.
- MoE 라우팅: 항상 켜진 공유 전문가 + 필요할 때 부르는 라우팅 전문가. 프롬프트 단위로 골라 고정.
- 메모리 벽 돌파: 20B는 플래시에, 활성분만 메모리에. 토큰 단위 swap을 포기한 게 핵심 설계.
- PCC 분담: 기본은 기기 안, 무거운 일만 프라이빗 클라우드로 — 프라이버시는 검증 가능하게.
핵심 메시지는 하나입니다. “전문가를 나눈 것”보다, 플래시 저장 + 프롬프트 단위 고정으로 모바일 메모리의 한계를 넘은 것이 이 모델의 진짜 혁신입니다.